这几天花了一些时间研究 GPU 上的 BVH 构建过程,发现其中一个关键前置步骤是实现 GPU 排序算法。相比于 CPU 的串行实现,在 GPU 上完成排序要复杂得多,挑战也更大。于是决定写一篇博客来总结这一过程。
算法实现用的GLSL的计算着色器,参考了Fast 4-way parallel radix sorting on GPUs。这篇论文对各环节细节的描述非常清晰,提供了极佳的算法参照模板,极大降低了从理论到 GPU 落地实现的门槛。
CPU上的基数排序
什么是基数排序?
实现 CPU 端的基数排序并不复杂。其核心在于预设一组对应的“计数桶”,根据待排序数字当前位的数值,将其分发至相应的桶中。当所有数字完成“入桶”后,再按桶的顺序依次收集并重写序列。通过从最低位到最高位的逐轮迭代,最终实现全局有序。
基数排序的灵活性在于你可以自由定义‘位’的含义。如果把数字看作十进制,就准备 10 个桶;如果是二进制,2 个桶就够了。甚至在理论上,你大可以心血来潮设置 11454 个桶,此时每个数都被视作‘11454 进制’下的一个数。当然,桶的数量并非越多越好,在工程实践中,我们需要在迭代次数与缓存命中率之间寻找那个性能平衡点。
下图展示了 4 个二进制数在最低有效位下进行单次排序迭代的逻辑示意。通过这一步骤,可以清晰地观察到数据是如何根据位信息进行重新排列的。
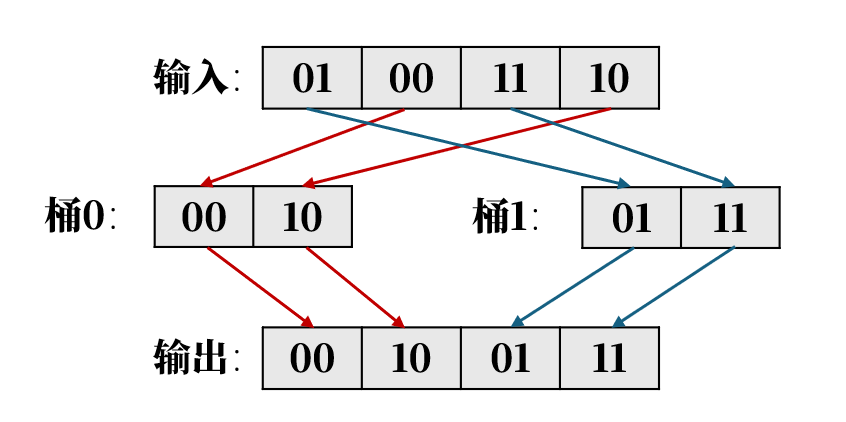
为什么要在GPU上做排序?
虽然 CPU 端的基数排序在理论复杂度上已经达到了 O(n),但在数据量爆炸的场景下,串行算法的效率提升空间已触及天花板。为了追求极致的吞吐量,将排序逻辑迁移至并行度更高的 GPU 平台是一个非常直观且可靠的思路。
另一个不可忽视的现实问题是:当整个流水线(例如用GPU构建LBVH)都在 GPU 上运行时,如果仅为了排序而通过 PCIe 总线进行数据往返转换(将数据传输到CPU做排序,随后再传输回GPU),其造成的延迟通常是不可接受的。为了避免这种昂贵的通信代价,开发高效的 GPU 原生排序算法显得尤为重要。
GPU上的基数排序
参考论文采用了 4-way(2-bit)基数排序 方案。每一轮迭代处理 2 个比特位,并预设 4 个桶进行并行计数。
事实是,将基数排序落地到 GPU 并非易事。参考论文给出的复杂图表,我们先不必纠结于 GPU 内部是如何进行并行计数的,而是应该理清图中每一组数据究竟代表了什么。只有弄懂了这些数据的含义,后续的并行分发与合并逻辑才会显得顺理成章。
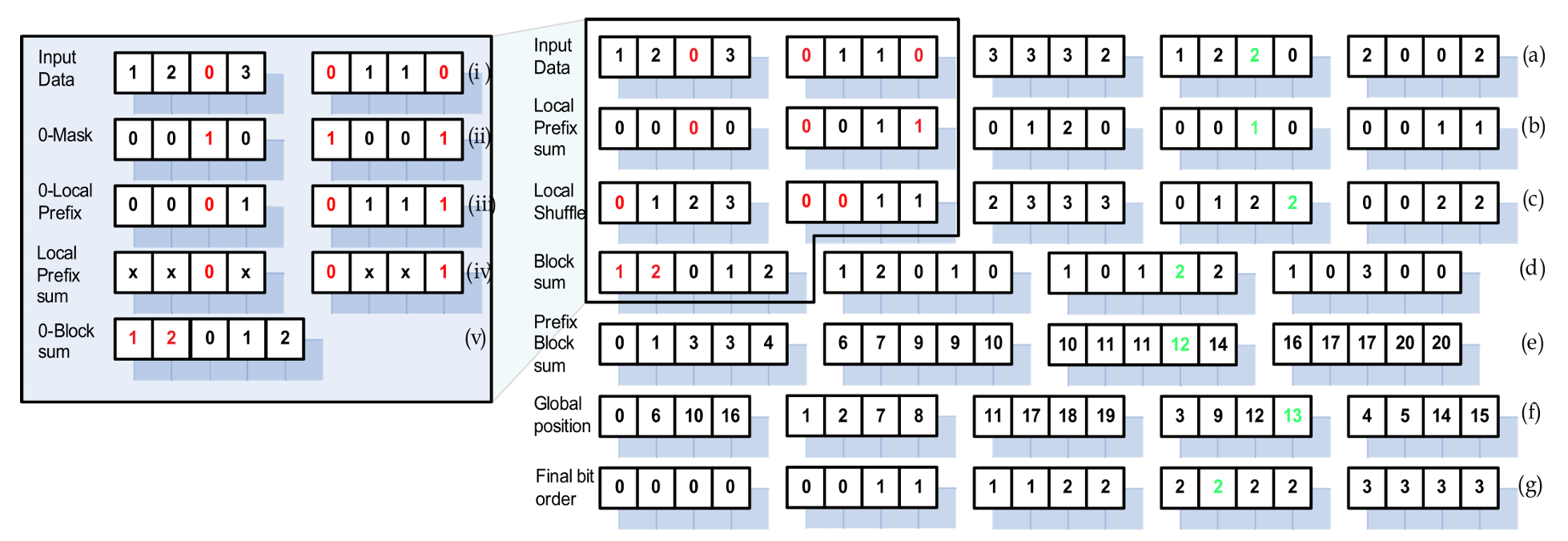
观察图表可以发现,数据被划分为不同的块(Blocks)。这是因为在 GPU 并行范式中,计算任务是以 工作组(Workgroup/Thread Block) 为基本单位进行调度的。
这种分块处理的设计,很大程度上受限于 GPU 的硬件架构。我们可以把工作组想象成一个容器,其最大容量通常只有 1024 个线程。面对只有 10 或 20 个数据的小规模场景,一个容器就足够了;但当数据量达到百万级时,单个容器根本无法承载。因此,我们需要让成百上千个工作组同时运转,每个组负责一小部分数据,从而通过大规模并行来缩短总体的排序耗时。
在理解了为什么需要将数据划分为不同的块之后,我们再来看看各组数据所代表的具体含义:
- Input Data(输入数据): 待排序的原始数据。在图中实际表示的是数据的基数,由于基数为 2 bit,因此图表中用 0–3 表示。
- Local Prefix Sum(局部前缀和): 表示当前基数在该块中出现的次数减 1。
- Local Shuffle(局部洗牌): 对局部块中的数据进行重新排序。
- Block Sum(块和): 统计每个块中各基数的数量。在图表中,从左到右的四组数据依次表示各块中 0、1、2、3 出现的次数。
- Prefix Block Sum(块和前缀和): 对 Block Sum 进行前缀和计算。
- Global Position(全局位置): 本轮排序后,输入数据在全局范围内的新位置。
每一轮迭代的核心任务很明确,就是计算输入数据在排序后的全局位置。该位置由 局部前缀和 与 块和前缀和 共同决定,公式如下:
Sorted Position=Pd[n]+m
其中,Pd[n]表示第 n 个块中基数 d 的块和前缀和,m 表示当前元素的局部前缀和。
以图表右侧的绿色数据为例:当前输入数据的基数为 2,局部前缀和为 1;它位于第 4 块,对应基数 2 的块和前缀和为 12。因此,该元素的最终全局位置为:
Sorted Position=12+1=13
现在我们已经掌握了计算所有元素新全局位置的方法,这一过程本身并不复杂,甚至可以说相当直观。然而,真正的挑战并不在于公式的推导,而在于如何在 GPU 上高效地完成 局部前缀和 与 块和前缀和 的计算。这才是实现过程中最关键的重点所在。为此,我们需要引入 GPU 的 扫描(Scan) 算法,也称为 并行前缀和(Parallel Prefix Sum)。
CPU上的扫描
对于接触过算法的同学来说,CPU 上的扫描操作一定不陌生。其中最常见的应用就是 前缀和 的计算,而在 CPU 上实现这一过程也非常简单。
1
2
3
| for (int i = 1; i < n; ++i) {
prefix[i] = prefix[i - 1] + data[i];
}
|
需要注意的是,扫描(Scan) 并不仅限于加法运算来计算前缀和。实际上,它可以结合任意满足结合律的运算符,例如按位与、按位或等。因此,扫描算法的应用范围远不止数值累加,而是可以灵活扩展到多种场景。
不过对于GPU上的基数排序,我们只需要用到加法运算即可。
GPU上的扫描
从 CPU 的扫描算法可以看出,每个元素的计算都依赖于前一个元素,形成了明确的依赖链。这种串行依赖关系在 GPU 上并不友好。设想一下,如果让每个线程分别负责一个元素的前缀和计算,那么每个线程都必须等待前一个线程完成,最终会导致极高的同步开销。
为了充分发挥 GPU 的高度并行性,Belloch 提出了适用于 GPU 的扫描算法,有效地解决了这一问题。
具体来说,GPU 上的扫描(Scan)通常分为两个阶段:归约/上扫(Reduce/Upsweep) 和 传播/下扫(Propagation/Downsweep)。
- 在归约阶段,算法通过并行归约的方式逐层累积信息,构建出一个树形结构,用于保存部分和或中间结果。
- 在传播阶段,算法再沿着树结构向下传递这些结果,从而为每个元素计算出最终的前缀值。
规约阶段
规约阶段的计算过程如图所示。假设输入数据共有 8 个元素,那么整个数组的规约需要进行 3 次迭代(即 log28=3 个 Pass):
- 第 1 个 Pass:计算相邻两个元素的和,需要 4 个线程并行完成;
- 第 2 个 Pass:计算相邻 4 个元素的和,需要 2 个线程并行完成;
- 第 3 个 Pass:计算所有元素的总和,此时只需 1 个线程。
需要注意的是,每一轮 Pass 的计算都依赖于上一轮的结果,因此形成了逐层归约的过程。
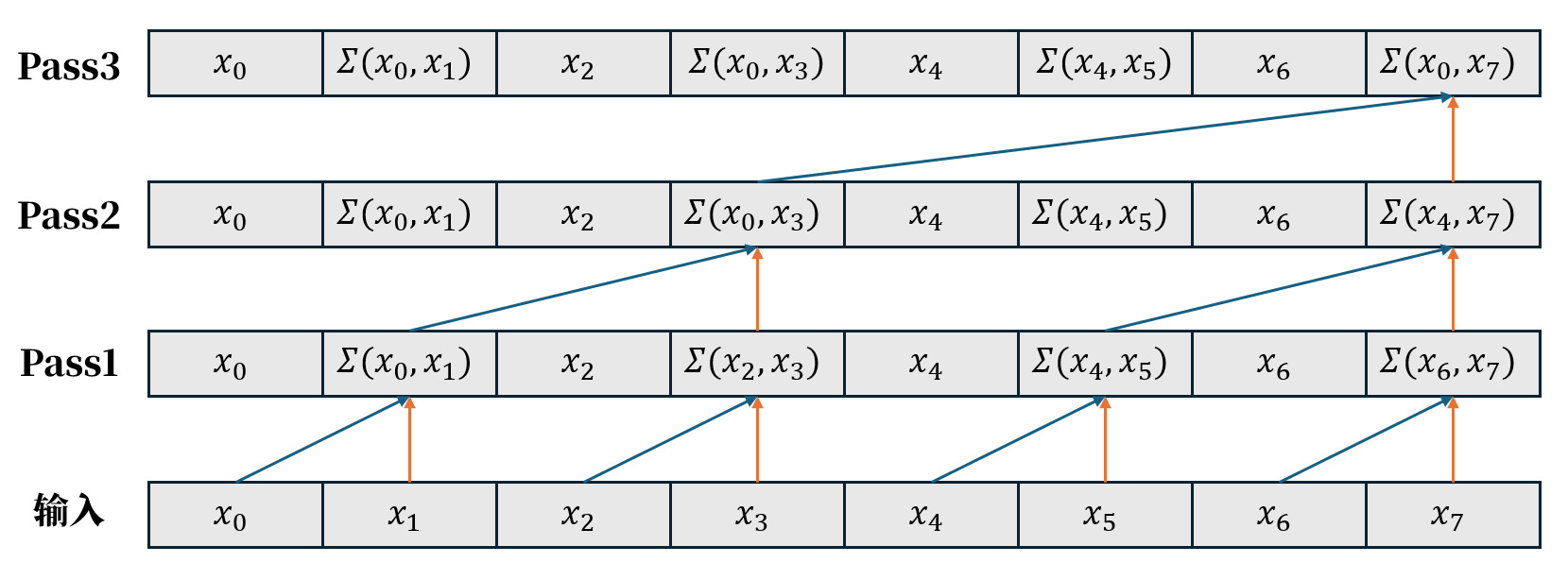
该过程对应的C++代码为:
1
2
3
4
5
6
7
8
9
10
11
12
| const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 8;
for (int stride = 1; stride < BLOCK_SIZE; stride <<= 1) {
for(int threadId = 0; threadId < THREAD_COUNT; threadId++)
{
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
data[index] += data[index - stride];
}
}
}
|
传播阶段
在规约阶段结束后,我们得到了一组中间结果。需要注意的是,最后一个元素实际上是所有元素的总和,这与 Inclusive Scan 的最后一个元素相同。然而在实际应用中,更常用的是 Exclusive Scan。因此需要对结果进行调整:最后一个元素应变为 ∑(x0,x6),而第一个元素则应设为 0。
其中,∑(x0,x6) 可以通过以下方式计算:
∑(x0,x6)=∑(x0,x3)+∑(x4,x5)+x6
不难发现,这同样是一个需要 3 次加法的迭代过程。
在此基础上,进入 传播阶段(Downsweep) 的计算过程,如图所示。
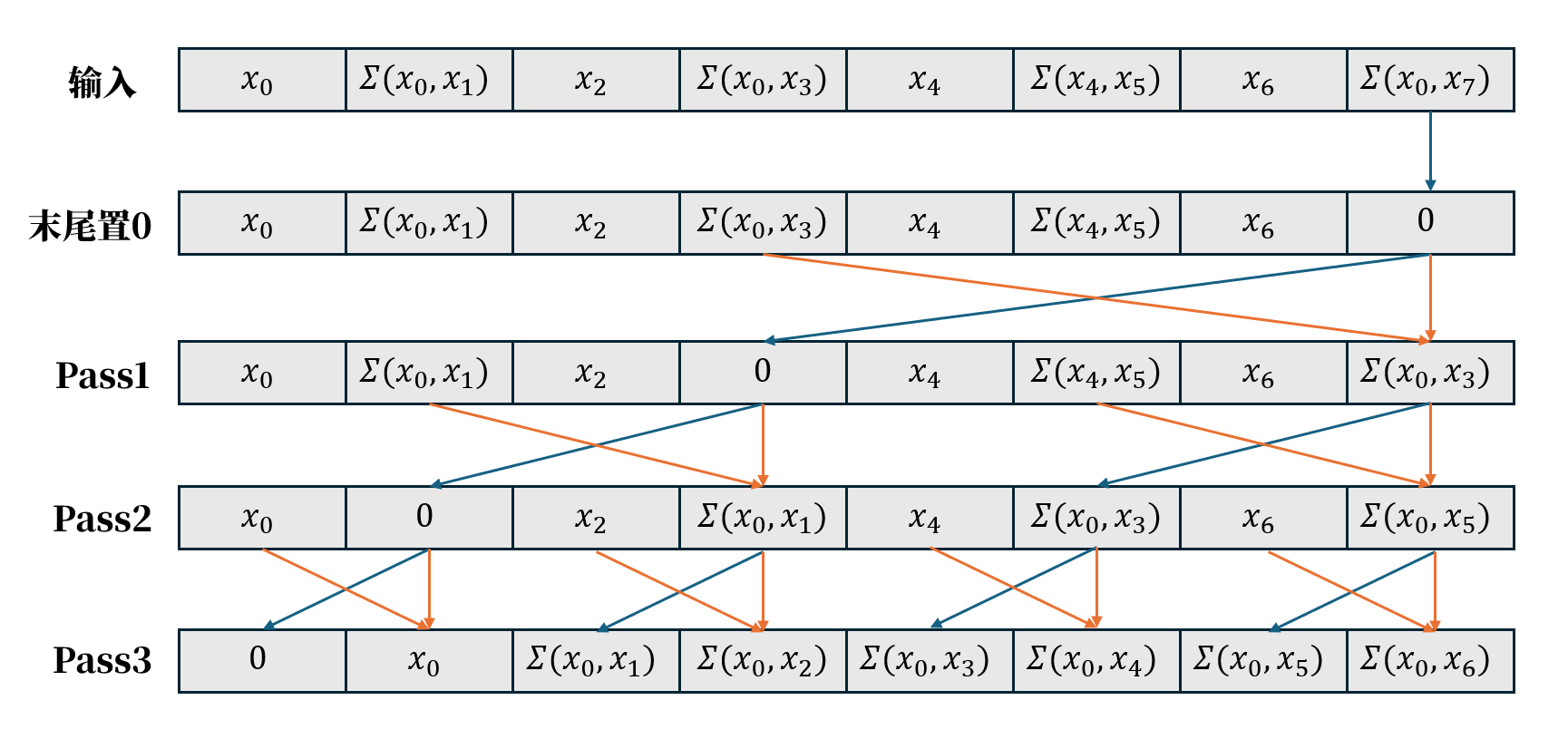
传播阶段在开始之前需要将末尾置0,随后进行3个Pass;
- 第 1 个 Pass: 将根节点的值传递给左右子节点,形成初始的分支累积结果。
- 第 2 个 Pass: 在每个子树中继续向下分发累积值,使得更小范围的节点能够获得正确的前缀信息。
- 第 3 个 Pass: 最终将累积值传递到叶子节点,为每个元素计算出其对应的前缀结果。
该过程对应的C++代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 8;
data[BLOCK_SIZE - 1] = 0;
for (int stride = BLOCK_SIZE / 2; stride > 0; stride >>= 1) {
for(int threadId = 0; threadId < THREAD_COUNT; threadId++)
{
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
temp = data[index - stride];
data[index - stride] = data[index];
data[index] += temp;
}
}
}
|
大规模数据
前面介绍的两个阶段主要针对小规模数据,它们通常在单个 GPU 工作组内完成。然而需要注意的是,工作组的最大线程数是有限的。当数据规模较大时,一个工作组只能计算出局部数据的扫描结果,无法直接覆盖全局。因此,在处理大规模数据时,还必须引入额外的步骤来整合各个工作组的局部结果,从而得到完整的全局扫描。
具体而言,我们需要将每个工作组对应数据的所有元素之和(即论文中的“块和”)存储到一段额外的全局显存中。在 GLSL 中,这通常对应为一个 SSBO(Shader Storage Buffer Object)。随后,再对这段 SSBO 执行前缀和计算,即再次应用前面介绍的 规约–传播(Reduce–Downsweep) 算法。
那么,所有元素的总和该如何求解呢?事实上,在规约阶段,我们已经将局部数据的累加结果存放在数组的最后一个元素中。因此,在传播阶段开始之前,只需将这些结果写入到 SSBO(Shader Storage Buffer Object) 中即可。
接下来,利用块和前缀和的 SSBO,我们还需要进行最后一个 Pass:将每个局部数据的前缀和依次加上对应的块和前缀和。这样,所有元素的全局前缀和就能被正确计算出来。
值得注意的是,如果 SSBO 的前缀和计算无法在单个工作组中完成,就必须采用递归方式继续分解与求解,直到最终得到完整的全局扫描结果。
基数排序在GPU上的具体实现
根据论文的描述,GPU 上的基数排序可以分为 三个 Pass:
- Pass 1
- Pass 2
- 输入:各工作组内 4 个基数的块和。
- 输出:4 个基数的块和前缀和。
- Pass 3
这里的第二个 Pass 本质上就是前面介绍的 GPU 扫描算法。不同之处在于,我们需要处理 4 个基数,而且每个基数还必须加上前一个基数的数量之和。实现这一点并不复杂:只需在计算 基数块和 的 块和前缀和 时,于传播阶段开始之前额外存储各个基数块和的 块和。随后,再由一个线程统一计算实际的 offset,即可得到正确的结果。
直接用语言描述还是比较抽象的。还是直接看代码吧~
Pass1
Pass1只需要一个计算着色器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| #version 430
layout (local_size_x = 128, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 0) buffer InputBuffer { int InData[]; };
layout(std430, binding = 1) buffer ShuffleBuffer { int LocalShuffle[]; };
layout(std430, binding = 2) buffer BlockSumBuffer { ivec4 BlockSum[]; };
uniform int u_elementCount;
uniform int u_bitShift;
const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 256;
shared ivec4 s_digit_total;
shared int s_offset[4];
shared ivec4 s_cnt[BLOCK_SIZE];
shared int s_local_shuffle[BLOCK_SIZE];
int ExtractBits(int data) {
return (data >> u_bitShift) & 3;
}
void main(){
uint threadId = gl_LocalInvocationID.x;
uint groupId = gl_WorkGroupID.x;
uint offset = groupId * BLOCK_SIZE;
uint idx1 = offset + threadId;
uint idx2 = offset + threadId + THREAD_COUNT;
int data1 = (idx1 < u_elementCount) ? InData[idx1] : 2147483647;
int data2 = (idx2 < u_elementCount) ? InData[idx2] : 2147483647;
int bits1 = ExtractBits(data1);
int bits2 = ExtractBits(data2);
s_cnt[threadId] = ivec4(0);
s_cnt[threadId + THREAD_COUNT] = ivec4(0);
if(idx1 < u_elementCount) s_cnt[threadId][bits1] = 1;
if(idx2 < u_elementCount) s_cnt[threadId + THREAD_COUNT][bits2] = 1;
barrier();
for (int stride = 1; stride < BLOCK_SIZE; stride <<= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
s_cnt[index] += s_cnt[index - stride];
}
barrier();
}
if (threadId == 0) {
s_digit_total = s_cnt[BLOCK_SIZE - 1];
BlockSum[groupId] = s_digit_total;
s_cnt[BLOCK_SIZE - 1] = ivec4(0);
s_offset[0] = 0;
s_offset[1] = s_digit_total.x;
s_offset[2] = s_digit_total.x + s_digit_total.y;
s_offset[3] = s_digit_total.x + s_digit_total.y + s_digit_total.z;
}
barrier();
for (int stride = BLOCK_SIZE / 2; stride > 0; stride >>= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
ivec4 temp = s_cnt[index - stride];
s_cnt[index - stride] = s_cnt[index];
s_cnt[index] += temp;
}
barrier();
}
int targetIdx1 = (idx1 < u_elementCount) ? (s_offset[bits1] + s_cnt[threadId][bits1]) : -1;
int targetIdx2 = (idx2 < u_elementCount) ? (s_offset[bits2] + s_cnt[threadId + THREAD_COUNT][bits2]) : -1;
barrier();
if(targetIdx1 != -1) s_local_shuffle[targetIdx1] = data1;
if(targetIdx2 != -1) s_local_shuffle[targetIdx2] = data2;
barrier();
if (idx1 < u_elementCount) LocalShuffle[idx1] = s_local_shuffle[threadId];
if (idx2 < u_elementCount) LocalShuffle[idx2] = s_local_shuffle[threadId + THREAD_COUNT];
}
|
Pass2
Pass2即GPU全局扫描算法,需要三个计算着色器,分别是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| #version 430
layout (local_size_x = 128, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 2) buffer DataBuffer { ivec4 InData[]; };
layout(std430, binding = 3) buffer ScanBuffer { ivec4 LocalScan[]; };
layout(std430, binding = 4) buffer BlockSumBuffer { ivec4 BlockSum[]; };
uniform int u_elementCount;
const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 256;
shared ivec4 s_digitTotal;
shared ivec4 s_data[BLOCK_SIZE];
void main(){
uint threadId = gl_LocalInvocationID.x;
uint groupId = gl_WorkGroupID.x;
uint offset = groupId * BLOCK_SIZE;
uint idx1 = offset + threadId;
uint idx2 = offset + threadId + THREAD_COUNT;
s_data[threadId] = (idx1 < u_elementCount) ? InData[idx1] : ivec4(0);
s_data[threadId + THREAD_COUNT] = (idx2 < u_elementCount) ? InData[idx2] : ivec4(0);
barrier();
for (int stride = 1; stride < BLOCK_SIZE; stride <<= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
s_data[index] += s_data[index - stride];
}
barrier();
}
if (threadId == 0) {
BlockSum[groupId] = s_data[BLOCK_SIZE - 1];
s_data[BLOCK_SIZE - 1] = ivec4(0);
}
barrier();
for (int stride = BLOCK_SIZE / 2; stride > 0; stride >>= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
ivec4 temp = s_data[index - stride];
s_data[index - stride] = s_data[index];
s_data[index] += temp;
}
barrier();
}
if (idx1 < u_elementCount) LocalScan[idx1] = s_data[threadId];
if (idx2 < u_elementCount) LocalScan[idx2] = s_data[threadId + THREAD_COUNT];
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| #version 430
layout (local_size_x = 128, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 4) buffer BlockSumBuffer { ivec4 BlockSum[]; };
uniform int u_blockCount;
const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 256;
shared ivec4 s_data[BLOCK_SIZE];
shared ivec4 s_componentOffset;
void main(){
uint threadId = gl_LocalInvocationID.x;
uint idx1 = threadId;
uint idx2 = threadId + THREAD_COUNT;
s_data[threadId] = (idx1 < u_blockCount) ? BlockSum[idx1] : ivec4(0);
s_data[threadId + THREAD_COUNT] = (idx2 < u_blockCount) ? BlockSum[idx2] : ivec4(0);
barrier();
for (int stride = 1; stride < BLOCK_SIZE; stride <<= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
s_data[index] += s_data[index - stride];
}
barrier();
}
if (threadId == 0) {
ivec4 total = s_data[BLOCK_SIZE - 1];
s_componentOffset.x = 0;
s_componentOffset.y = total.x;
s_componentOffset.z = total.x + total.y;
s_componentOffset.w = total.x + total.y + total.z;
s_data[BLOCK_SIZE - 1] = ivec4(0);
}
barrier();
for (int stride = BLOCK_SIZE / 2; stride > 0; stride >>= 1) {
int index = (int(threadId) + 1) * stride * 2 - 1;
if (index < BLOCK_SIZE) {
ivec4 temp = s_data[index - stride];
s_data[index - stride] = s_data[index];
s_data[index] += temp;
}
barrier();
}
if (idx1 < u_blockCount) {
BlockSum[idx1] = s_data[threadId] + s_componentOffset;
}
if (idx2 < u_blockCount) {
BlockSum[idx2] = s_data[threadId + THREAD_COUNT] + s_componentOffset;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #version 430
layout (local_size_x = 256, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 3) buffer ScanBuffer {
ivec4 GlobalScan[];
};
layout(std430, binding = 4) readonly buffer BlockSumBuffer {
ivec4 PrefixBlockSum[];
};
uniform int u_elementCount;
void main()
{
uint globalId = gl_GlobalInvocationID.x;
uint groupId = gl_WorkGroupID.x;
if(globalId < u_elementCount)
{
ivec4 offset = PrefixBlockSum[groupId];
GlobalScan[globalId] += offset;
}
}
|
Pass3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| #version 430
layout (local_size_x = 128, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 1) buffer ShuffleBuffer { int LocalShuffle[]; };
layout(std430, binding = 2) buffer BlockSumBuffer { ivec4 BlockSum[]; };
layout(std430, binding = 3) buffer PreBlockSumBuffer { ivec4 PreBlockSum[]; };
layout(std430, binding = 5) buffer FinalOrderBuffer {int FinalOrder[]; };
uniform int u_elementCount;
uniform int u_bitShift;
const int THREAD_COUNT = 128;
const int BLOCK_SIZE = 256;
shared int s_offset[4];
int ExtractBits(int data) {
return (data >> u_bitShift) & 3;
}
void main(){
uint threadId = gl_LocalInvocationID.x;
uint groupId = gl_WorkGroupID.x;
if (threadId == 0) {
ivec4 digit_total = BlockSum[groupId];
s_offset[0] = 0;
s_offset[1] = digit_total.x;
s_offset[2] = digit_total.x + digit_total.y;
s_offset[3] = digit_total.x + digit_total.y + digit_total.z;
}
barrier();
uint offset = groupId * BLOCK_SIZE;
uint localIdx1 = threadId;
uint idx1 = offset + localIdx1;
if(idx1 < u_elementCount)
{
int data = LocalShuffle[idx1];
int bits = ExtractBits(data);
int in_bucket_idx = int(localIdx1) - s_offset[bits];
int global_final_pos = PreBlockSum[groupId][bits] + in_bucket_idx;
FinalOrder[global_final_pos] = data;
}
uint localIdx2 = threadId + THREAD_COUNT;
uint idx2 = offset + localIdx2;
if(idx2 < u_elementCount)
{
int data = LocalShuffle[idx2];
int bits = ExtractBits(data);
int in_bucket_idx = int(localIdx2) - s_offset[bits];
int global_final_pos = PreBlockSum[groupId][bits] + in_bucket_idx;
FinalOrder[global_final_pos] = data;
}
}
|
依次调用这5个计算着色器,即可完成GPU的基数排序~
当然这里的计算着色器在性能上还需要做额外的考究,我这里直接将最终的结果用一个新的SSBO存储起来了,实际上可以直接存放在InputData的SSBO中。另外这边也没有对Bank Conflict做额外的优化。论文中还提到一个用于快速验证是否有序的提前终止算法,能够在很多情况下带来可观的性能提升……总之,能做的事情还有很多。
完整代码放在 HoshioRenderer/RadixSortV1。