古法渲染:DisneyBSDF的实现 这是一篇 DisneyBSDF 实现笔记,主要记录踩坑过程中的三个核心模块: 玻璃材质BSDF的实现细节; 玻璃材质BSDF 与 DisneyBRDF 的整合; VNDF 可见性法线分布采样。 在玻璃材质 BSDF 分支中,个人感觉最棘手的部分是 透射率(transmittance) 的处理。由于光线在介质边界来回折射,参数和方向需要反复转换,实现时很容易搞混符号和相对关系,写起来 2026-04-21 真实感渲染 > BSDF #真实感渲染 #PBR #BSDF
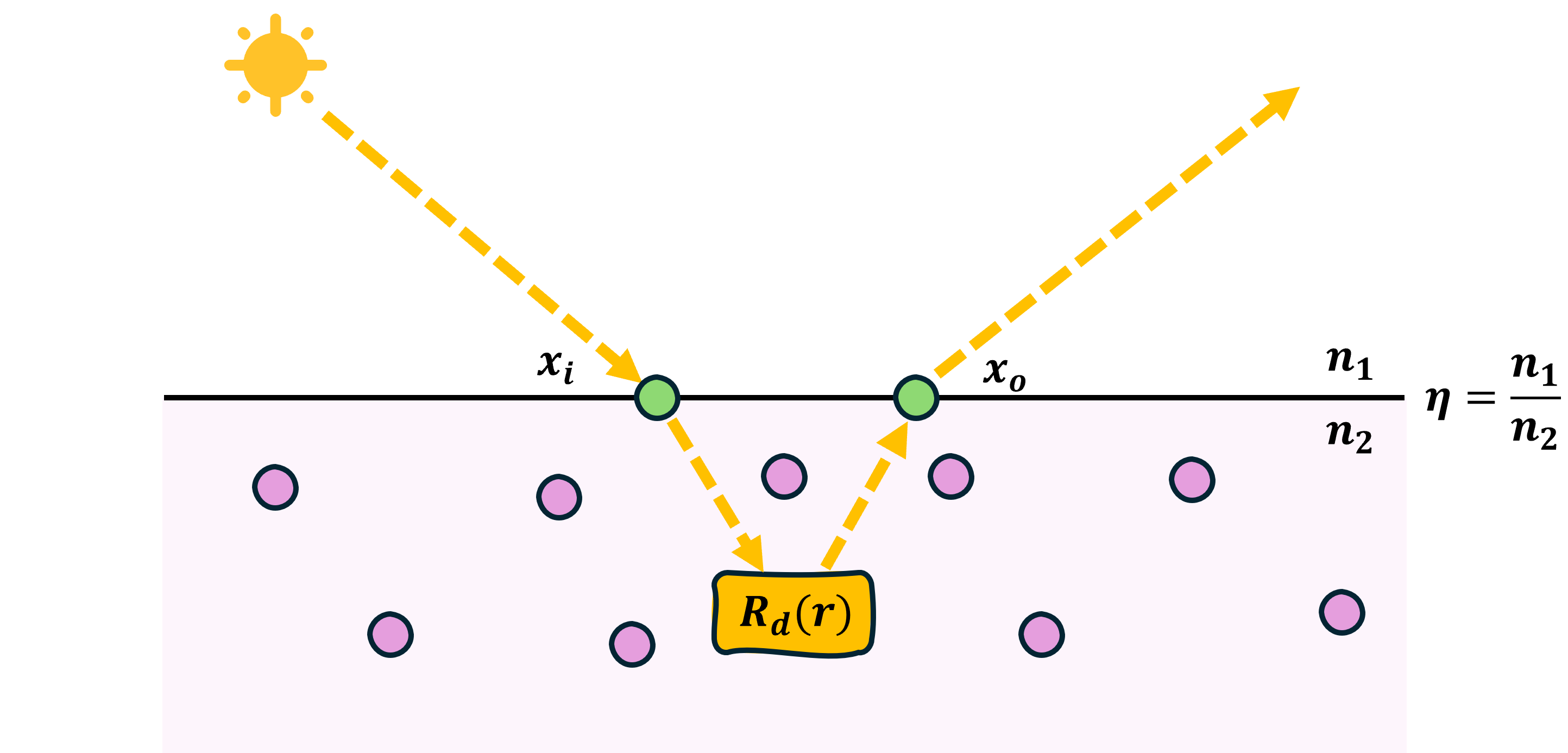
真实感渲染:BSSRDF 前一篇文章里,我们已经把体积渲染里最核心的理论部分过了一遍:从吸收、外散射、内散射和发光这四种基本行为出发,一步步拼出了辐射传输方程的基本形式。到了这里,我们总算算是手握理解 BSSRDF 的钥匙,也是时候来揭开它的神秘面纱了。 BSSRDF,全称 Bidirectional Surface Scattering Reflectance Distribution Function,通常可以翻译为双 2026-04-02 真实感渲染 > BSSRDF #真实感渲染 #PBR #BSSRDF #次表面散射
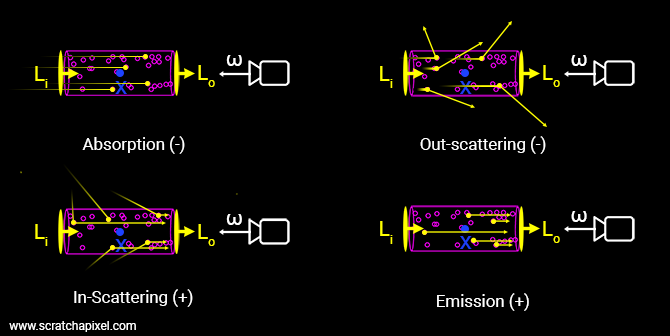
真实感渲染:Volume Rendering 体积渲染(Volume Rendering),图形学渲染领域的又一座大山。在 NeRF 和 3DGS 还没有出现之前,体积渲染主要被用来处理各种参与介质,比如牛奶、火焰、云层这类“看得见内部结构”的东西。这些介质有一个共同点:它们内部都充满了大量微小粒子,光在其中传播时,会不断和这些粒子发生相互作用,比如吸收、散射,甚至发光。也正因为如此,参与介质的渲染要比普通表面渲染复杂得多。 描述这一过程的核 2026-04-01 真实感渲染 > 体积渲染 #真实感渲染 #PBR #体积渲染
真实感渲染:BSDF 前段时间写了一个 GPU BVH 构建器,顺手跑了个漫反射光追测了下效果。 虽然看着挺像那么一回事的,但还是有很多令人不太舒服的伪影,也不知道是代码的问题还是没有用重要性采样的原因,反正是懒得 Debug 了。 不过既然光追的框架已经完成了,也是时候升级成 BSDF 看看效果了。 这篇首先会简单的介绍一下 BSDF,随后回顾一下渲染方程和微表面理论,这篇文章不会涉及到具体的代码实现。 光的行为与 2026-03-30 真实感渲染 > BSDF #真实感渲染 #PBR #BSDF
高性能计算:GPU上的BVH (2) 前文介绍了当前最高效的 GPU BVH 构建算法(LBVH)。这些方法通过对整个数组进行莫顿码预排序,从而避免了在 BVH 构建过程中对局部数据进行额外排序。此外,它们均采用了基数树的数据结构,并充分利用其特性,形成了极为高效的构建流程。 然而,尽管 LBVH 在构建速度上表现突出,却难以直接应用于高效的光线追踪场景。原因在于,LBVH 的设计仅以构建速度为唯一评价指标,而忽略了另一个关键因素—— 2026-03-20 高性能计算 > BVH #高性能计算 #GPU #BVH
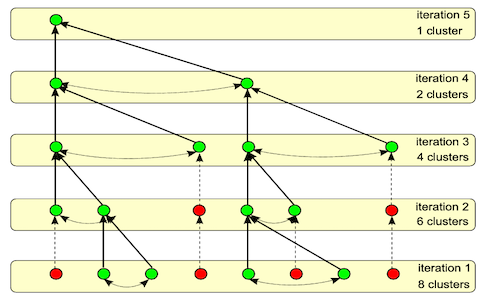
高性能计算:GPU上的BVH (1) 前两篇文章分别介绍了 GPU 基数排序和莫顿码。随着这些前期准备工作的完成,我们终于可以进入正题——在 GPU 上构建 BVH。 在学术界,关于 GPU 构建 BVH 的研究成果十分丰富。论文1 Fast BVH Construction on GPUs 首次将莫顿码应用于 GPU 构建 BVH,并提出了 LBVH 与 SPH BVH 的构建方法。其中,LBVH 的构建过程需要在显存中执行多个步骤 2026-03-20 高性能计算 > BVH #高性能计算 #GPU #BVH
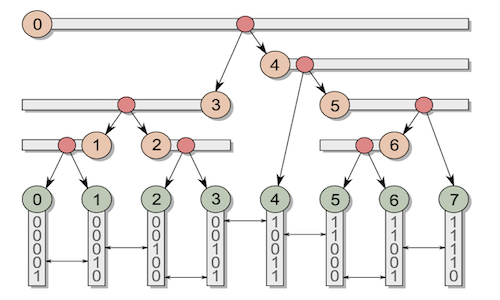
高性能计算:莫顿码 在 CPU 中,图像通常采用线性存储方式,即行优先顺序。然而,这种方式对 GPU 并不友好。原因在于,GPU 在执行片段着色器等操作时,往往需要同时访问某个像素及其周围的邻域像素,例如双线性插值。 若采用线性排列存储,当访问一个 2×2 像素块时,上方两个像素与下方两个像素在内存中的位置相距较远,导致 GPU 必须进行两次独立的内存访问。 如果能够将相邻的 2×2 像素块存储在一起,便可将两次访问 2026-03-10 高性能计算 > 莫顿码 #高性能计算 #GPU #莫顿码
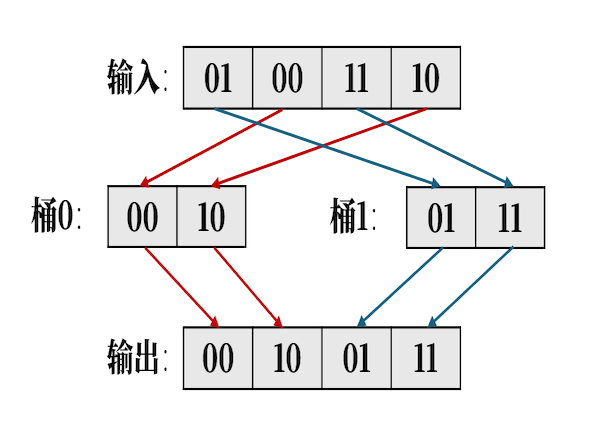
高性能计算:GPU上的基数排序 这几天花了一些时间研究 GPU 上的 BVH 构建过程,发现其中一个关键前置步骤是实现 GPU 排序算法。相比于 CPU 的串行实现,在 GPU 上完成排序要复杂得多,挑战也更大。于是决定写一篇博客来总结这一过程。 算法实现用的GLSL的计算着色器,参考了Fast 4-way parallel radix sorting on GPUs。这篇论文对各环节细节的描述非常清晰,提供了极佳的算法参照模板 2026-03-09 高性能计算 > 排序 #高性能计算 #GPU #基数排序
流动的点描:基于 WCSPH 流体动力学的图像风格化实践 最近我在做一个和点描(Stippling)相关的小项目:根据图片的灰度信息生成大量点的位置。实现这一目标的方法其实很多,比如误差扩散、Voronoi 质心剖分等等。每种方法都有它独特的美感和挑战。 在尝试这些算法的过程中,我突然想到:这些生成的点不就是一个个粒子吗?如果把它们看作粒子,那是不是可以借用平滑粒子流体动力学(SPH)的思想来探索新的可能性?或许能让点描的分布更自然、更具动态感。 虽然 2026-02-17 非真实感渲染 > 风格化渲染 #流体动力学 #点描 #风格化
虚幻引擎用SceneViewExtension实现简单后处理效果 前言 前两篇文章介绍了虚幻引擎中计算管线和图形管线的调用流程,但示例中仅在某个 Actor 的 BeginPlay() 中调用了一次。如果希望在每一帧都执行这个自定义管线,又该如何实现呢? 这时就需要借助 SceneViewExtension。SceneViewExtension 为我们提供了渲染流程中多个阶段的 Hook,既涵盖游戏线程,也包含渲染线程。通过重载对应的虚函数,我们可以实现例如: 2026-01-31 虚幻引擎 > 渲染依赖图 > SceneViewExtension #虚幻引擎 #渲染依赖图 #RDG #SceneViewExtension