高性能计算:莫顿码
在 CPU 中,图像通常采用线性存储方式,即行优先顺序。然而,这种方式对 GPU 并不友好。原因在于,GPU 在执行片段着色器等操作时,往往需要同时访问某个像素及其周围的邻域像素,例如双线性插值。
若采用线性排列存储,当访问一个 2×2 像素块时,上方两个像素与下方两个像素在内存中的位置相距较远,导致 GPU 必须进行两次独立的内存访问。
如果能够将相邻的 2×2 像素块存储在一起,便可将两次访问合并为一次,从而显著提升访问效率。同时,这种存储方式也更有利于 GPU 线程之间的协同工作。
那么,是否存在这样的存储方式呢?答案是肯定的,其名为 莫顿码(Morton Code)。在这种排列方式下,图像像素会按照莫顿码顺序进行组织,如下图所示。
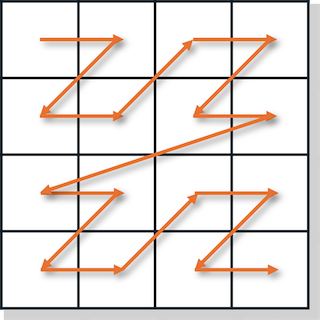
不难发现莫顿码的顺序形成了一个Z字形曲线,因此也被称为Z-order curve。
除了在 GPU 中的图像存储之外,莫顿码(Morton Code) 还被广泛应用于三维空间中的对象组织及相关算法。例如,它常用于 GPU 并行构建 LBVH。因此,本篇文章的核心主题是:如何根据三维坐标 构建具有局部连续性的莫顿码。
三维莫顿码
三维莫顿码的构建并不复杂,其核心思想是将三维坐标 的各比特位依次交错排列,从而生成具有空间局部性的编码:
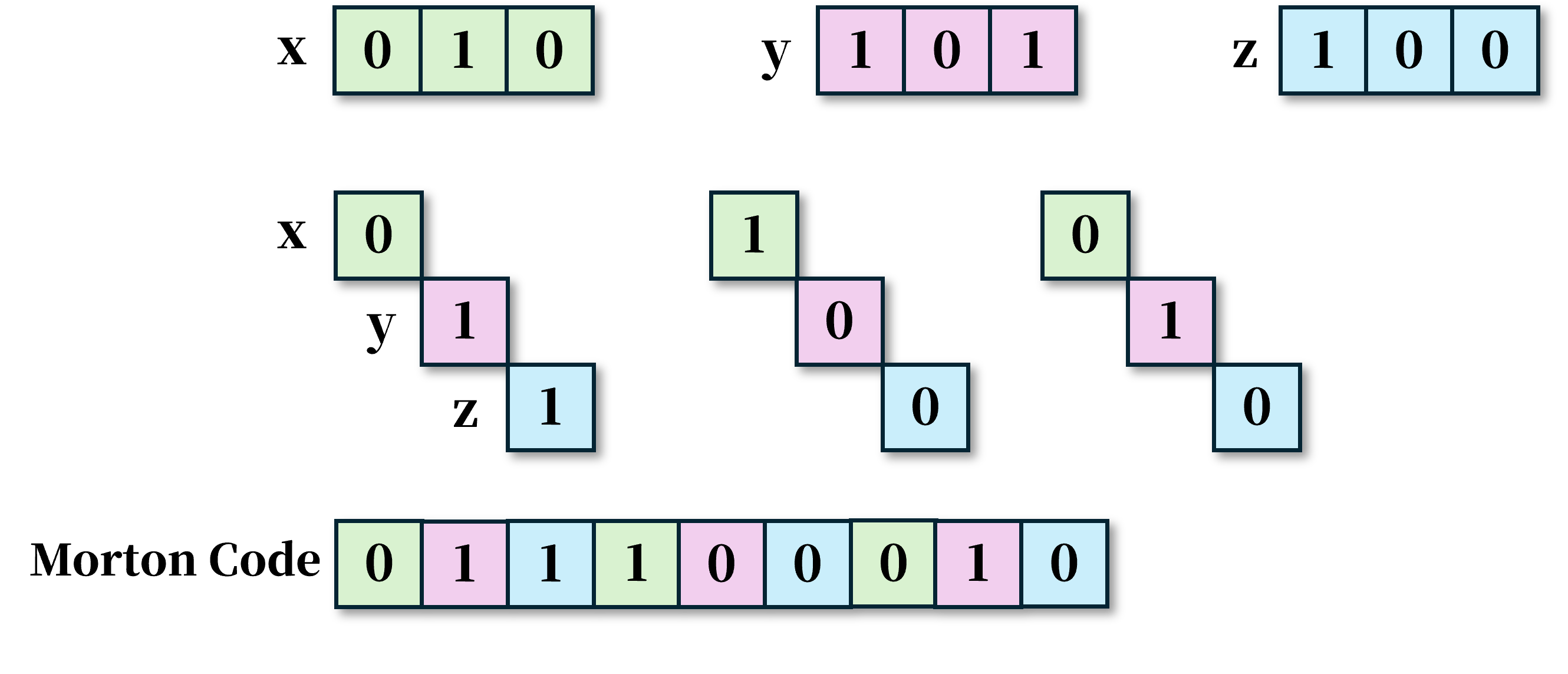
在图例中,假设输入的三维坐标为 。我们只需将该坐标的各个分量分别转换为二进制表示,并依次交错排列它们的比特位。经过这一过程,最终得到的莫顿码结果为 226。
莫顿码对三维坐标的输入并非毫无限制。通过观察图例可以发现,当输入数据为 3 比特时,其对应的莫顿码长度为 9 比特。而在 GPU 中,我们通常使用一个整型或无符号整型来表示索引,这就限制了莫顿码的最大长度为 32 比特。换言之,对应到三维坐标时,每个分量最多只能使用 10 比特,即数值不能超过 1023。
根据图例中的莫顿码构建过程,我们可以很轻松地得到对应的代码:
1 | |
这种构造方式在结果上毫无疑问是准确的,然而在性能上却称不上优秀:原因在于它逐位交错排列坐标分量的比特位,每次迭代都涉及多次移位与按位操作,整体运算开销较大。
高效莫顿码生成:位扩展与掩码方法
为了加速莫顿码的构建,我们可以借助分治思想来处理坐标分量的二进制表示。
我们的目标是将一个不超过 10 位有效位的数扩展为 32 位,其中在相邻的有效比特之间插入 2 个 0 填充位:
- 输入:
0000 0000 0000 0000 0000 00ab cdef ghij - 输出:
0000 a00b 00c0 0d00 e00f 00g0 0h00 i00j
如果仅仅展示输入与输出,难免显得生硬。为了更清晰地说明这一算法,我们需要对 有效位 进行新的定义:有效位不再局限于单个比特,而是可以由多个比特组合而成。例如,当我们将 4 个比特视为一个有效位时,就以 4 位为一个整体进行处理。
在有了这一新的定义之后,后续的逻辑就变得清晰了。我们首先将 8 个比特视为一个有效位,并在扩展时在两个有效位之间插入 2 个填充位(即值为 0 的 16 比特填充)。接着,将 4 个比特作为一个有效位,再然后是 2 个比特,最后细化到单个比特。通过这种逐步分解与扩展的方式,最终即可得到目标结果。
一个具体例子
为了更直观地展示计算过程,我们假设输入数据为: 0000 0000 0000 0000 0000 0011 1111 1111
8位有效位
首先将 8 位视为一个有效位,输入数据可以表示为 a b c d,其中:
a = 0000 0000 = 0b = 0000 0000 = 0c = 0000 0011d = 1111 1111
为了简化表达,这里约定:全为 0 的位分组记为 0,全为 1 的位分组记为 1,而末位为 1、其余位为 0 的位分组记为 2。在 8 位有效位的情况下,0 = 0000 0000,1 = 1111 1111,2= 0000 0001。
此时,包含最低10比特的位即位有效位,即 c 和 d。我们需要将 0 0 c d 转换为 c 0 0 d。实现方法是:将 0 0 c d 左移两个有效位并按位或,再与 1 0 0 1 按位与即可。为了简化描述,可以用一次乘法来表示左移并按位或的操作,整体逻辑为:
(0 0 c d × 0 2 0 2) & 1 0 0 1 = c 0 0 d
其中:
0 0 c d = 0000 0000 0000 0000 0000 0011 1111 11110 2 0 2 = 0000 0000 0000 0001 0000 0000 0000 00010 0 c d * 0 1 0 1 = c d c d = 0000 0011 1111 1111 0000 0011 1111 1111(0 0 c d * 0 2 0 2) & 1 0 0 1 = c 0 0 d = 0000 0011 0000 0000 0000 0000 1111 1111
4位有效位
随后我们将 4 位视为一个有效位。上一轮的输出 0000 0011 0000 0000 0000 0000 1111 1111 可以表示为 a b c d e f g h。
此时,包含初始输入数据最低 10 比特的分组即为有效位,即:
b = 0011g = 1111h = 1111
我们需要将 0 b 0 0 0 0 g h 转换为 0 b 0 0 g 0 0 h,也就是在有效位之间插入两个有效位长度的零填充。其计算逻辑为:
(0 b 0 0 0 0 g h × 0 0 0 0 0 2 0 2) & 0 1 0 0 1 0 0 1 = 0 b 0 0 g 0 0 h
最终结果为0000 0011 0000 0000 1111 0000 0000 1111。
2位有效位
同样的,2位有效位也是相同的逻辑,上一轮输出可以表示为ab cd ef gh ij kl mn op,此时,包含初始输入数据的最低10比特的位分组即为有效位,即:
d = 11i = 11j = 11o = 11p = 11
现在将00 0d 00 00 ij 00 00 op转化成 00 0d 00 i0 0j 00 o0 0p,同样是插入两个有效位长度的0填充,其计算逻辑为:
(00 0d 00 00 ij 00 00 op × 00 00 00 00 00 00 02 02) & 10 01 00 10 01 00 10 01 = 00 0d 00 i0 0j 00 o0 0p
最终结果为0000 0011 0000 1100 0011 0000 1100 0011。
1位有效位
最后一轮也是相同的逻辑,就不过多解释了,最终的计算逻辑为:
(var × 0b0101) & 0100 1001 0010 0100 1001 0010 0100 1001
最终结果为0000 1001 0010 0100 1001 0010 0100 1001。
具体代码
将例子中的二进制转化为十六进制,即可很轻松地得到高效莫顿编码的代码:
1 | |
莫顿码并不仅限于整型数据,浮点数同样可以生成对应的莫顿码。具体而言,我们通常先将浮点数归一化到 的范围,再将其映射到 的整数空间。虽然这一过程会带来一定的精度损失,但莫顿码的主要作用是确定空间数据的索引顺序,因此这种精度损失在实际应用中影响并不显著。
曲线可视化
最后附上一张莫顿码的曲线可视化,用的是我自己写的渲染器~