前段时间写了一个 GPU BVH 构建器,顺手跑了个漫反射光追测了下效果。
虽然看着挺像那么一回事的,但还是有很多令人不太舒服的伪影,也不知道是代码的问题还是没有用重要性采样的原因,反正是懒得 Debug 了。
不过既然光追的框架已经完成了,也是时候升级成 BSDF 看看效果了。
这篇首先会简单的介绍一下 BSDF,随后回顾一下渲染方程和微表面理论,这篇文章不会涉及到具体的代码实现。
光的行为与BSDF
在图形学中,光的行为通常可以概括为三种基本形式:吸收、散射和发光。
吸收(Absorption) :指光在传播过程中,其能量逐渐被介质吸收而减弱的现象。在一些均匀介质中(例如常见的空气),光通常沿直线传播,但其强度会随着传播距离的增加而逐渐衰减。
散射(Scattering) :通常发生在参与介质中(例如牛奶,云朵等)。当光进入此类介质后,会不断与其中的微小颗粒发生相互作用,使光被重新分配到不同方向传播。该过程满足能量守恒,即散射后的总能量不超过散射前的能量。
发光(Emission) :发生在自发光物体中。这类物体能够向各个方向发射新的光,从而成为光的来源。
然而,BSDF(Bidirectional Scattering Distribution Function,双向散射分布函数) 中的“散射”与上述在参与介质中的散射有着本质区别。BSDF 实际上是一种用于描述表面光照行为的模型,它统一了 BRDF(Bi-directional Transmit Distribution Function,双向反射分布函数) 和 BTDF(Bi-directional Scattering Distribution Function, 双向透射分布函数) 。因此,这里的“散射”并非指光在介质中被随机改变方向的过程,而是特指光在物体表面发生的反射 与透射 等相互作用。
我自己曾经对 BSDF 就存在过很长一段时间的误解,一度以为它描述的是参与介质中的散射过程,因此始终对其抱有一种“高深莫测”的敬畏之心。实际上,BSDF 仅用于刻画光在物体表面的反射与透射行为。
而真正涉及参与介质中散射效应时,则需要引入另一个更加复杂的主题——体积渲染(Volume Rendering) 。在这一框架下,我们所使用的也不再是经典的渲染方程,而是更为一般的辐射传输方程(Radiative Transfer Equation, RTE) 。当然,这篇文章并不会涉及这部分内容。
渲染方程
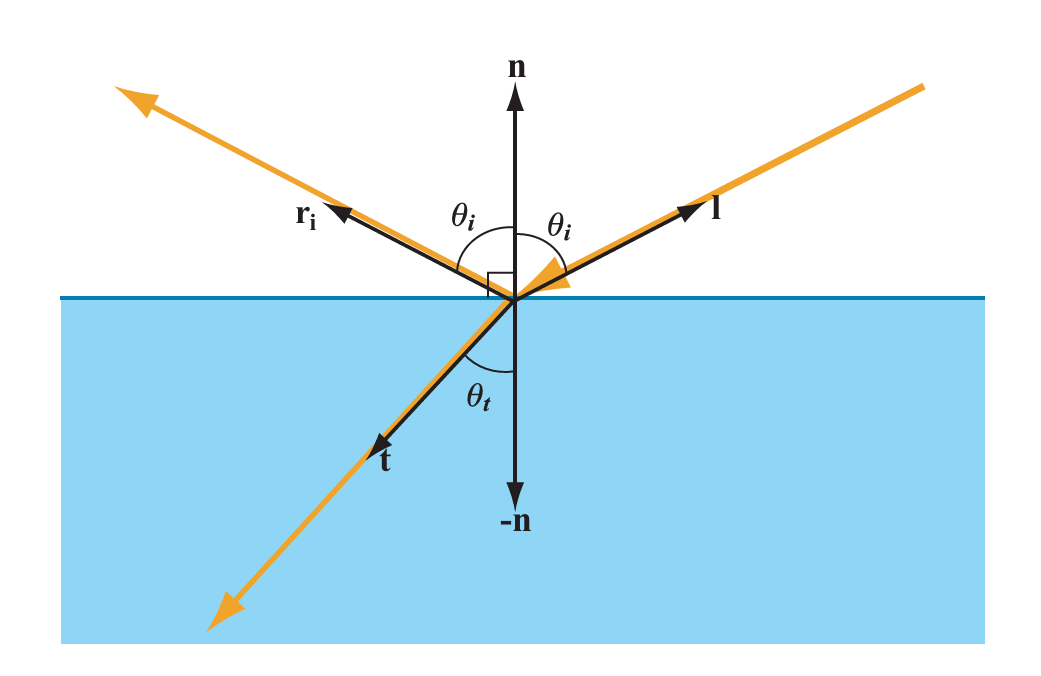
回顾一下渲染方程:
L o ( p , ω o ) = L e ( p , ω o ) + ∫ Ω L i ( p , ω i ) f s ( p , ω i , ω o ) ( n ⋅ ω i ) d ω i (1) L_o(p, \omega_o) = L_e(p,\omega_o) + \int_{\Omega}L_i(p,\omega_i)f_s(p,\omega_i,\omega_o)(n\cdot \omega_i) \mathrm d \omega_i \tag{1}
L o ( p , ω o ) = L e ( p , ω o ) + ∫ Ω L i ( p , ω i ) f s ( p , ω i , ω o ) ( n ⋅ ω i ) d ω i ( 1 )
其中,L o L_o L o L i L_i L i L e L_e L e p p p ω i \omega_i ω i ω o \omega_o ω o f s f_s f s ω i \omega_i ω i ω o \omega_o ω o ω i \omega_i ω i ω o \omega_o ω o
从物理意义上看,渲染方程描述的是:在点 p p p ω o \omega_o ω o
需要注意的是,这里的 f s f_s f s 宏观物体表面 的散射行为,由两部分组成,分别是 f r f_r f r f t f_t f t
f s = f r + f t f_s = f_r + f_t
f s = f r + f t
也就是说,BSDF 可以看作是 BRDF 与 BTDF 的统一表示形式:前者描述光在表面的反射行为,后者则描述光的透射行为。
为了推导 f s f_s f s 微表面模型(Microfacet Model) 来进行分析。
微表面模型
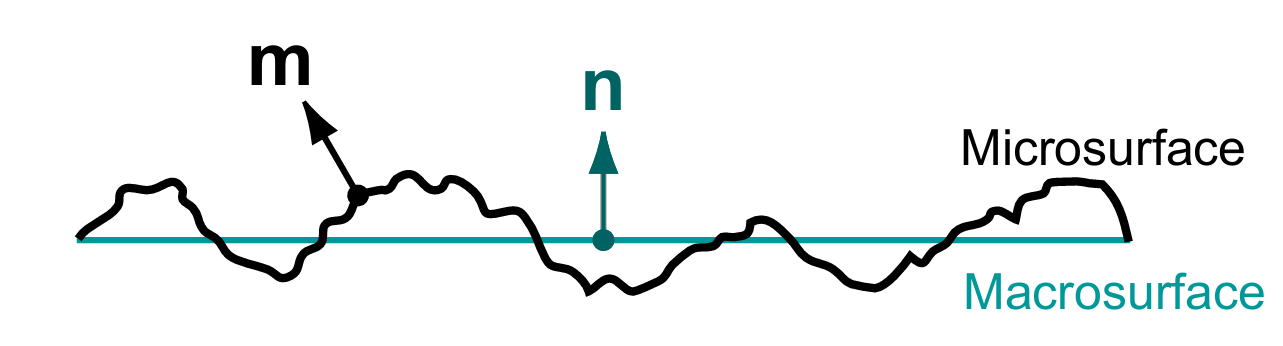
正如前文所述,在实际求解渲染方程时,我们通常是在 宏观表面 上进行计算。无论是现实世界中的物体表面,还是 3D 模型中的几何表面,在我们的建模与计算中,往往都被近似为 理想的平滑表面 。然而在微观尺度下,不同材质的表面实际上具有复杂的结构特征,呈现出各种细微的凹凸起伏。
显然,直接在微观层面求解渲染方程几乎是不可行的,这太复杂了。如果能够将这些复杂的微观结构行为,转化为一种简洁而有效的宏观表达形式,将极大地方便渲染方程的求解。
这正是微表面模型(Microfacet Model)的核心思想:将光在表面上的微观相互作用,映射为宏观层面的反射与透射行为 。
如图所示,微表面模型的目标,是将由黑色曲线表示的微观表面(Microsurface),等效为由青色曲线表示的宏观表面(Macrosurface),从而在保持物理合理性的同时,大幅简化计算过程。
显然,这种从微观表面到宏观表面的转化需要借助积分来完成。通常我们会假设微观表面由无数个极小的理想平面 组成,而每一个这样的平面元都会发生理想的镜面反射与折射 。
为了便于后续表述,我们先约定如下符号:
v \mathbf{v} v n \mathbf{n} n m \mathbf{m} m f s ( i , o , n ) f_s(\mathbf{i},\mathbf{o},\mathbf{n}) f s ( i , o , n ) n \mathbf{n} n i \mathbf{i} i o \mathbf{o} o p p p n \mathbf{n} n p p p f s f_s f s f s m ( i , o , n ) f_s^m(\mathbf{i},\mathbf{o},\mathbf{n}) f s m ( i , o , n ) f r , f r m , f t , f t m f_r,f_r^m,f_t,f_t^m f r , f r m , f t , f t m
描述微观表面通常需要以下三个关键要素:
微表面法线分布函数 D ( m ) D(\mathbf{m}) D ( m ) m \mathbf{m} m 几何项(阴影-遮蔽函数) G ( i , o , m ) G(\mathbf{i},\mathbf{o},\mathbf{m}) G ( i , o , m ) 微观表面 BSDF f s m f_s^m f s m
微表面法线分布函数 D
微表面法线分布函数 D ( m ) D(\mathbf{m}) D ( m ) s r − 1 sr^{-1} s r − 1 m \mathbf{m} m
具体而言,对于一块总面积为 A A A d ω m \mathrm{d}\omega_m d ω m m \mathbf{m} m D ( m ) d ω m D(\mathbf{m})\,\mathrm{d}\omega_m D ( m ) d ω m
A ⋅ D ( m ) d ω m A \cdot D(\mathbf{m})\, \mathrm{d}\omega_m
A ⋅ D ( m ) d ω m
也就是说,D ( m ) D(\mathbf{m}) D ( m )
需要注意的是,微观表面的总面积通常大于宏观表面的面积,因此有:
1 ≤ ∫ D ( m ) d ω m 1 \leq \int D(\mathbf{m})\, \mathrm{d}\omega_m
1 ≤ ∫ D ( m ) d ω m
这一点其实是直观可理解的:在示意图中,用黑色曲线表示的微观表面由于存在起伏,其“实际长度”(或面积)显然大于用青色曲线表示的宏观表面。
但这似乎与概率密度函数的定义相矛盾——按照常规定义,概率密度函数在其定义域上的积分应当等于 1。这里的关键在于:D ( m ) D(\mathbf{m}) D ( m ) 度量基准 与宏观表面并不一致。
为了得到与宏观表面相一致的概率分布,我们需要在积分中引入一个投影因子,将微观表面的面积投影到宏观表面上。通常这个投影项为 ( n ⋅ m ) (\mathbf{n} \cdot \mathbf{m}) ( n ⋅ m )
∫ Ω D ( m ) ( n ⋅ m ) d ω m = 1 \int_\Omega D(\mathbf{m})(\mathbf{n} \cdot \mathbf{m})\, \mathrm{d}\omega_m = 1
∫ Ω D ( m ) ( n ⋅ m ) d ω m = 1
这样处理后,积分结果才对应于宏观表面上的面积比例分布,也符合概率密度函数的归一化要求。
换句话说,前面积分结果大于等于 1,本质上是因为我们是在宏观表面的参考系 下,对微观表面(实际起伏的表面)上进行度量(即青色曲线为单位长度)。如果我们是在微观表面的参考系 下对微观表面进行度量,那∫ D ( m ) d ω m \int D(\mathbf{m})\, \mathrm{d}\omega_m ∫ D ( m ) d ω m
几何项(阴影-遮蔽函数) G
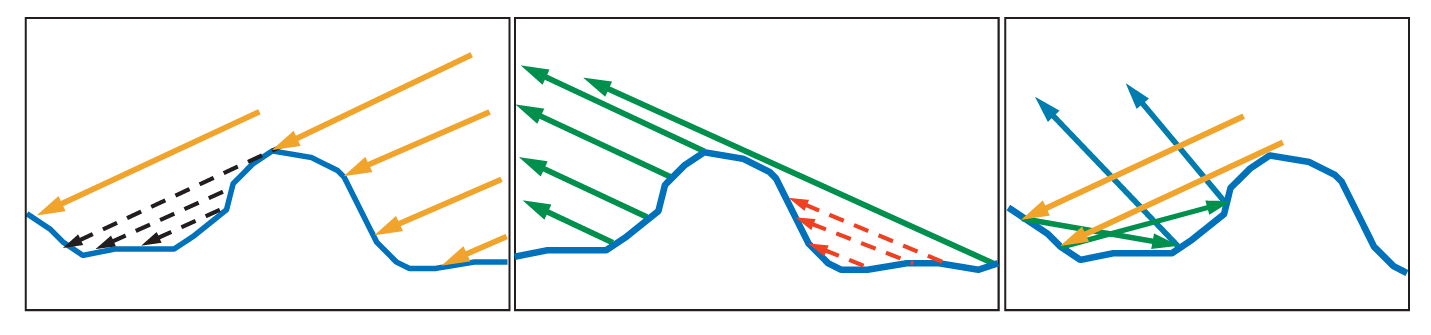
几何项(阴影-遮蔽函数)G ( i , o , m ) G(\mathbf{i},\mathbf{o},\mathbf{m}) G ( i , o , m ) i \mathbf{i} i o \mathbf{o} o
如图所示,微表面之间可能发生多种遮挡情况,例如入射光被其他微表面遮挡(阴影),或者反射后的光在出射路径上被阻挡(遮蔽)。因此,并不是所有入射光都能有效参与最终的出射贡献。
本质上来看,几何项的核心作用在于对这类可见性问题进行建模:即在给定入射与出射方向的情况下,只有一部分光线能够真正完成从入射到出射的传播过程,其余部分则会被微观结构所遮挡。
计算宏观 BSDF
有了微表面法线分布函数 D ( m ) D(\mathbf{m}) D ( m ) G ( i , o , m ) G(\mathbf{i},\mathbf{o},\mathbf{m}) G ( i , o , m ) f s f_s f s
f s ( i , o , n ) = ∫ ∣ i ⋅ m i ⋅ n ∣ f s m ( i , o , m ) ∣ o ⋅ m o ⋅ n ∣ G ( i , o , m ) D ( m ) d ω m (2) f_s(\mathbf{i},\mathbf{o},\mathbf{n})=\int\left|\frac{\mathbf{i}\cdot\mathbf{m}}{\mathbf{i}\cdot\mathbf{n}}\right|f_s^m(\mathbf{i},\mathbf{o},\mathbf{m})\left|\frac{\mathbf{o}\cdot\mathbf{m}}{\mathbf{o}\cdot\mathbf{n}}\right|G(\mathbf{i},\mathbf{o},\mathbf{m})D(\mathbf{m}) \mathrm d\mathbf{\omega}_m \tag{2}
f s ( i , o , n ) = ∫ i ⋅ n i ⋅ m f s m ( i , o , m ) o ⋅ n o ⋅ m G ( i , o , m ) D ( m ) d ω m ( 2 )
其中f s m f_s^m f s m 菲涅尔项(Fresnel Term) 来描述光在该微表面上发生反射与透射的比例:当入射角接近掠射角时,反射分量会显著增加,而透射分量相应减小。
在上述积分表达式中,还需要引入两个修正因子:∣ i ⋅ m i ⋅ n ∣ \left|\frac{\mathbf{i}\cdot\mathbf{m}}{\mathbf{i}\cdot\mathbf{n}}\right| i ⋅ n i ⋅ m ∣ o ⋅ m o ⋅ n ∣ \left|\frac{\mathbf{o}\cdot\mathbf{m}}{\mathbf{o}\cdot\mathbf{n}}\right| o ⋅ n o ⋅ m
试想一束辐射亮度为L L L ( i ⋅ n ) (\mathbf{i}\cdot\mathbf{n}) ( i ⋅ n ) L × ( i ⋅ n ) L\times (\mathbf{i}\cdot\mathbf{n}) L × ( i ⋅ n )
然而,在微表面模型中,我们关注的是具有法向 n \mathbf{n} n ( i ⋅ m ) (\mathbf{i}\cdot\mathbf{m}) ( i ⋅ m ) L × ( i ⋅ m ) L\times (\mathbf{i}\cdot\mathbf{m}) L × ( i ⋅ m )
因此,从宏观到微观的转换过程中,就需要乘以修正因子 ∣ i ⋅ m i ⋅ n ∣ \left|\frac{\mathbf{i}\cdot\mathbf{m}}{\mathbf{i}\cdot\mathbf{n}}\right| i ⋅ n i ⋅ m
从微观层面将出射量重新转换回宏观层面时,也需要一个投影修正因子。其原因在于,辐射亮度 (radiance)的定义依赖于单位投影面积:
L = d 2 Φ d ω d A cos θ L=\frac{\mathrm d^2 \Phi}{\mathrm d \omega \mathrm d A \cos\theta}
L = d ω d A cos θ d 2 Φ
因此,对于同一束沿 o \mathbf o o n \mathbf n n m \mathbf m m
L m a r c o = d 2 Φ d ω d A ∣ o ⋅ n ∣ L_{marco}=\frac{\mathrm d^2 \Phi}{\mathrm d \omega \,\mathrm d A \left|\mathbf{o}\cdot\mathbf{n}\right|}
L ma rco = d ω d A ∣ o ⋅ n ∣ d 2 Φ
L m i r c o = d 2 Φ d ω d A ∣ o ⋅ m ∣ L_{mirco}=\frac{\mathrm d^2 \Phi}{\mathrm d \omega \,\mathrm d A \left|\mathbf{o}\cdot\mathbf{m}\right|}
L mi rco = d ω d A ∣ o ⋅ m ∣ d 2 Φ
于是两者满足关系
L m a r c o L m i r c o = ∣ o ⋅ m o ⋅ n ∣ \frac{L_{marco}}{L_{mirco}}= \left|\frac{\mathbf{o}\cdot\mathbf{m}}{\mathbf{o}\cdot\mathbf{n}}\right|
L mi rco L ma rco = o ⋅ n o ⋅ m
因此,当我们把以微表面为参考定义的出射辐射亮度换算为以宏观表面为参考的出射辐射亮度时,需要乘上修正因子∣ o ⋅ m o ⋅ n ∣ \left|\frac{\mathbf{o}\cdot\mathbf{m}}{\mathbf{o}\cdot\mathbf{n}}\right| o ⋅ n o ⋅ m
微表面镜面 BSDF
正如前文所述,在微表面模型中,每一个微小表面都被视为一块理想镜面,因此只会发生理想的镜面反射与折射 。这意味着:对于给定的入射方向 i \mathbf{i} i
为了刻画这种“只在特定方向上有贡献”的分布,我们通常引入 狄拉克函数(Dirac Delta Function) 进行描述:
δ ( t ) = { ∞ t = 0 0 o t h e r w i s e \left. \delta(t) = \left\{
\begin{array}
{cc}\infty & t = 0\\
0 & \mathrm{otherwise}
\end{array}\right.\right. δ ( t ) = { ∞ 0 t = 0 otherwise
该函数满足如下归一化性质:
∫ δ ( t ) d t = 1 \int\delta(t)dt = 1
∫ δ ( t ) d t = 1
因此,它非常适合用于表示理想镜面中“能量集中在唯一方向”的特性。我们可以定义 义δ ω o ( s , o ) \delta_{\omega_o}(\mathbf{s},\mathbf{o}) δ ω o ( s , o ) s \mathbf{s} s o \mathbf{o} o
进一步地,引入反射(或透射)系数 ρ \rho ρ
f s m ( i , o , n ) = ρ δ ω o ( s , o ) ∣ o ⋅ m ∣ f_s^m(\mathbf{i},\mathbf{o},\mathbf{n}) = \rho\frac{\delta_{\omega_o}(\mathbf{s},\mathbf{o})}{\left|\mathbf{o} \cdot\mathbf{m}\right|}
f s m ( i , o , n ) = ρ ∣ o ⋅ m ∣ δ ω o ( s , o )
那么这里为什么又要除以 ∣ o ⋅ m ∣ \left|\mathbf{o} \cdot\mathbf{m}\right| ∣ o ⋅ m ∣ 投影面积 定义的,而 BSDF 的定义需要满足能量守恒关系。
因此我们这里除以 ∣ o ⋅ m ∣ \left|\mathbf{o} \cdot\mathbf{m}\right| ∣ o ⋅ m ∣
上述表达还可以进一步变形。在原始形式中,我们需要通过判断s = o \mathbf{s}=\mathbf{o} s = o m \mathbf{m} m i \mathbf{i} i 半程向量(half-vector) h \mathbf{h} h
在镜面反射情况下,h \mathbf{h} h m \mathbf{m} m i \mathbf{i} i o \mathbf{o} o h = i + o ∥ i + o ∥ \mathbf{h} = \frac{\mathbf{i} + \mathbf{o}}{\|\mathbf{i} + \mathbf{o}\|} h = ∥ i + o ∥ i + o h = m \mathbf{h}=\mathbf{m} h = m
基于这一变换,微表面镜面 BSDF 可改写为:
f s m ( i , o , n ) = ρ δ ω o ( h ( i , o ) , m ) ∣ o ⋅ m ∣ ∥ ∂ ω h ∂ ω o ∥ (3) f_s^m(\mathbf{i},\mathbf{o},\mathbf{n}) = \rho\frac{\delta_{\omega_o}(\mathbf{h(\mathbf{i},\mathbf{o})},\mathbf{m})}{\left|\mathbf{o} \cdot\mathbf{m}\right|}\left\|\frac{\partial\omega_{\mathbf{h}}}{\partial\omega_{\mathbf{o}}}\right\| \tag{3}
f s m ( i , o , n ) = ρ ∣ o ⋅ m ∣ δ ω o ( h ( i , o ) , m ) ∂ ω o ∂ ω h ( 3 )
公式(3)引入了一个雅可比行列式(Jacobian determinant) ∥ ∂ ω h ∂ ω o ∥ \left\|\frac{\partial \omega_h}{\partial \omega_o}\right\| ∂ ω o ∂ ω h
∫ ρ δ ω o ( h ( i , o ) , m ) ∣ o ⋅ m ∣ ∥ ∂ ω h ∂ ω o ∥ d ω o = ∫ ρ δ ω o ( h ( i , o ) , m ) ∣ o ⋅ m ∣ d ω h \begin{align*}
&\int \rho\frac{\delta_{\omega_o}(\mathbf{h(\mathbf{i},\mathbf{o})},\mathbf{m})}{\left|\mathbf{o} \cdot\mathbf{m}\right|}\left\|\frac{\partial\omega_{\mathbf{h}}}{\partial\omega_{\mathbf{o}}}\right\| \,\mathrm d\omega_o\\
= & \int \rho\frac{\delta_{\omega_o}(\mathbf{h(\mathbf{i},\mathbf{o})},\mathbf{m})}{\left|\mathbf{o} \cdot\mathbf{m}\right|}\ \mathrm d\omega_h
\end{align*} = ∫ ρ ∣ o ⋅ m ∣ δ ω o ( h ( i , o ) , m ) ∂ ω o ∂ ω h d ω o ∫ ρ ∣ o ⋅ m ∣ δ ω o ( h ( i , o ) , m ) d ω h
现在只要求解雅可比行列式 ∥ ∂ ω h ∂ ω o ∥ \left\|\frac{\partial\omega_{\mathbf{h}}}{\partial\omega_{\mathbf{o}}}\right\| ∂ ω o ∂ ω h f s m f_s^m f s m f r m f_r^m f r m f t m f_t^m f t m
雅可比行列式的求解有点麻烦(还是太菜了^ _ ^),所以就直接给出结果了。
反射项的雅可比行列式为:
∥ ∂ ω h r ∂ ω o ∥ = 1 4 ∥ o ⋅ h r ∥ \left\|\frac{\partial\omega_{\mathbf{h_r}}}{\partial\omega_{\mathbf{o}}}\right\|
=\frac{1}{4\left\|\mathbf{o} \cdot\mathbf{h_r}\right\|} ∂ ω o ∂ ω h r = 4 ∥ o ⋅ h r ∥ 1
透射项的雅可比行列式为:
∥ ∂ ω h t ∂ ω o ∥ = η o 2 ∣ o ⋅ h t ∣ ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 \left\|\frac{\partial\omega_{\mathbf{h_t}}}{\partial\omega_{\mathbf{o}}}\right\|
=\frac{\eta_{o}^{2}\left|\mathbf{o}\cdot\mathbf{h_{t}}\right|}{\left(\eta_{i}(\mathbf{i}\cdot\mathbf{h_{t}})+\eta_{o}(\mathbf{o}\cdot\mathbf{h_{t}})\right)^{2}} ∂ ω o ∂ ω h t = ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 η o 2 ∣ o ⋅ h t ∣
分别代入公式(3),并将 ρ \rho ρ F F F f r m f_r^m f r m f t m f_t^m f t m
f r m ( i , o , m ) = F ( i , m ) δ ω m ( h r , m ) 4 ( i ⋅ h r ) 2 f t m ( i , o , m ) = ( 1 − F ( i , m ) ) δ ω m ( h t , m ) η o 2 ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 \begin{align*}
f_r^m(\mathbf{i},\mathbf{o},\mathbf{m}) & =F(\mathbf{i},\mathbf{m})\frac{\delta_{\mathbf{\omega}_m}(\mathbf{h}_\mathbf{r},\mathbf{m})}{4(\mathbf{i}\cdot\mathbf{h}_\mathbf{r})^2} \\
f_t^m(\mathbf{i},\mathbf{o},\mathbf{m})&=(1-F(\mathbf{i},\mathbf{m}))\frac{\mathbf{\delta}_{\mathbf{\omega}_m}(\mathbf{h}_\mathrm{t},\mathbf{m})\mathbf{\eta}_o^2}{(\mathbf{\eta}_i(\mathbf{i}\cdot\mathbf{h}_\mathrm{t})+\mathbf{\eta}_o(\mathbf{o}\cdot\mathbf{h}_\mathrm{t}))^2}
\end{align*} f r m ( i , o , m ) f t m ( i , o , m ) = F ( i , m ) 4 ( i ⋅ h r ) 2 δ ω m ( h r , m ) = ( 1 − F ( i , m )) ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 δ ω m ( h t , m ) η o 2
将微表面的反射项 f r m f_r^m f r m f t m f_t^m f t m
f s ( i , o , m ) = f r ( i , o , m ) + f t ( i , o , m ) f r ( i , o , n ) = F ( i , h r ) G ( i , o , h r ) D ( h r ) 4 ∣ i ⋅ n ∣ ∣ o ⋅ n ∣ f t ( i , o , n ) = ∣ i ⋅ h t ∣ ∣ o ⋅ h t ∣ ∣ i ⋅ n ∣ ∣ o ⋅ n ∣ η o 2 ( 1 − F ( i , h t ) ) G ( i , o , h t ) D ( h t ) ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 \begin{align*}
f_s(\mathbf{i},\mathbf{o},\mathbf{m}) &=f_r(\mathbf{i},\mathbf{o},\mathbf{m})+f_t(\mathbf{i},\mathbf{o},\mathbf{m}) \\
f_r(\mathbf{i},\mathbf{o},\mathbf{n})&=\frac{F(\mathbf{i},\mathbf{h}_\mathbf{r})G(\mathbf{i},\mathbf{o},\mathbf{h}_\mathbf{r})D(\mathbf{h}_\mathbf{r})}{4\left|\mathbf{i}\cdot\mathbf{n}\right|\left|\mathbf{o}\cdot\mathbf{n}\right|} \\
f_t\left(\mathbf{i},\mathbf{o},\mathbf{n}\right)&=\frac{\left|\mathbf{i}\cdot\mathbf{h}_\mathrm{t}\right|\left|\mathbf{o}\cdot\mathbf{h}_\mathrm{t}\right|}{\left|\mathbf{i}\cdot\mathbf{n}\right|\left|\mathbf{o}\cdot\mathbf{n}\right|}\frac{\mathbf{\eta}_o^2\left(1-F(\mathbf{i},\mathbf{h}_\mathrm{t})\right)G(\mathbf{i},\mathbf{o},\mathbf{h}_\mathrm{t})D(\mathbf{h}_\mathrm{t})}{\left(\mathbf{\eta}_i(\mathbf{i}\cdot\mathbf{h}_\mathrm{t})+\mathbf{\eta}_o(\mathbf{o}\cdot\mathbf{h}_\mathrm{t})\right)^2}
\end{align*} f s ( i , o , m ) f r ( i , o , n ) f t ( i , o , n ) = f r ( i , o , m ) + f t ( i , o , m ) = 4 ∣ i ⋅ n ∣ ∣ o ⋅ n ∣ F ( i , h r ) G ( i , o , h r ) D ( h r ) = ∣ i ⋅ n ∣ ∣ o ⋅ n ∣ ∣ i ⋅ h t ∣ ∣ o ⋅ h t ∣ ( η i ( i ⋅ h t ) + η o ( o ⋅ h t ) ) 2 η o 2 ( 1 − F ( i , h t ) ) G ( i , o , h t ) D ( h t )
其中 η i \eta_i η i η o \eta_o η o
选择 D、G、F 项
D、G 和 F 有很多可选形式,比如LearnOpenGL中介绍的经验公式。
微表面法线分布函数 D:
N D F G G X T R ( n , h , α ) = α 2 π ( ( n ⋅ h ) 2 ( α 2 − 1 ) + 1 ) 2 NDF_{GGXTR}(n,h,\alpha)=\frac{\alpha^2}{\pi((n\cdot h)^2(\alpha^2-1)+1)^2}
N D F GGXTR ( n , h , α ) = π (( n ⋅ h ) 2 ( α 2 − 1 ) + 1 ) 2 α 2
其中α \alpha α
1 2 3 4 5 6 7 8 9 10 float D_GGX_TR(vec3 N, vec3 H, float a) float a2 = a*a; float NdotH = max (dot (N, H), 0.0 ); float NdotH2 = NdotH*NdotH; float nom = a2; float denom = (NdotH2 * (a2 - 1.0 ) + 1.0 ); return nom / denom;
几何项(阴影-遮蔽函数) G:
G S c h l i c k G G X ( n , v , k ) = n ⋅ v ( n ⋅ v ) ( 1 − k ) + k k = ( α + 1 ) 2 8 G ( n , v , l , k ) = G s u b ( n , v , k ) G s u b ( n , l , k ) \begin{align*}
G_{\mathrm{SchlickGG}X}(n,v,k) & =\frac{n\cdot v}{(n\cdot v)(1-k)+k} \\
k & =\frac{(\alpha+1)^2}{8} \\
G(n,v,l,k)&=G_{sub}(n,v,k)G_{sub}(n,l,k)
\end{align*} G SchlickGG X ( n , v , k ) k G ( n , v , l , k ) = ( n ⋅ v ) ( 1 − k ) + k n ⋅ v = 8 ( α + 1 ) 2 = G s u b ( n , v , k ) G s u b ( n , l , k )
其中α \alpha α
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 float GeometrySchlickGGX(float NdotV, float k)float nom = NdotV;float denom = NdotV * (1.0 - k) + k;return nom / denom;float GeometrySmith(vec3 N, vec3 V, vec3 L, float k)float NdotV = max (dot (N, V), 0.0 );float NdotL = max (dot (N, L), 0.0 );float ggx1 = GeometrySchlickGGX(NdotV, k);float ggx2 = GeometrySchlickGGX(NdotL, k);return ggx1 * ggx2;
菲涅尔方程 F:
F S c h l i c k ( h , v , F 0 ) = F 0 + ( 1 − F 0 ) ( 1 − ( h ⋅ v ) ) 5 F_{Schlick}(h,v,F_0)=F_0+(1-F_0)(1-(h\cdot v))^5
F S c h l i c k ( h , v , F 0 ) = F 0 + ( 1 − F 0 ) ( 1 − ( h ⋅ v ) ) 5
其中F 0 F_0 F 0
1 2 3 4 5 6 7 vec3 F0 = vec3 (0.04 ); mix (F0, surfaceColor.rgb, metalness);vec3 fresnelSchlick(float cosTheta, vec3 F0) return F0 + (1.0 - F0) * pow (1.0 - cosTheta, 5.0 );
采样
这一部分涉及重要性采样(Importance Sampling) 的内容。对于给定的一条入射方向 i \mathbf{i} i o \mathbf{o} o p o ( o ) p_o(\mathbf{o}) p o ( o )
f s ( i , o , n ) ( o ⋅ n ) f_s(\mathbf {i},\mathbf {o},\mathbf {n})(\mathbf {o} \cdot \mathbf {n})
f s ( i , o , n ) ( o ⋅ n )
成正比,就可以显著降低采样方差。
在路径追踪中,对应样本的权重为:
w e i g h t ( o ) = f s ( i , o , n ) ∣ o ⋅ n ∣ p o ( o ) (4) \mathrm{weight}(\mathbf{o}) = \frac{f_s(\mathbf{i}, \mathbf{o}, \mathbf{n})\, |\mathbf{o}\cdot\mathbf{n}|}{p_o(\mathbf{o})} \tag{4}
weight ( o ) = p o ( o ) f s ( i , o , n ) ∣ o ⋅ n ∣ ( 4 )
如果满足
p o ( o ) ∝ f s ( i , o , n ) ∣ o ⋅ n ∣ p_o(\mathbf{o}) \propto f_s(\mathbf{i}, \mathbf{o}, \mathbf{n})\, |\mathbf{o} \cdot \mathbf{n}|
p o ( o ) ∝ f s ( i , o , n ) ∣ o ⋅ n ∣
即
p o ( o ) = c ⋅ f s ( i , o , n ) ∣ o ⋅ n ∣ p_o(\mathbf{o}) = c \cdot f_s(\mathbf{i}, \mathbf{o}, \mathbf{n})\, |\mathbf{o} \cdot \mathbf{n}|
p o ( o ) = c ⋅ f s ( i , o , n ) ∣ o ⋅ n ∣
那么所有样本的权重将为常数,此时方差为 0(理想情况)。
然而,直接在 o \mathbf{o} o p o ( o ) p_o(\mathbf{o}) p o ( o ) 先对微表面法向 m \mathbf{m} m o \mathbf{o} o 。
微表面法向的概率密度分布为:
p m ( m ) = D ( m ) ∣ m ⋅ n ∣ p_m(\mathbf{m}) = D(\mathbf{m})\, |\mathbf{m} \cdot \mathbf{n}|
p m ( m ) = D ( m ) ∣ m ⋅ n ∣
随后,通过变量变换(由 m → o \mathbf{m} \rightarrow \mathbf{o} m → o p m p_m p m p o p_o p o
p o ( o ) = p m ( m ) ∥ ∂ ω h ∂ ω o ∥ p_o(\mathbf{o}) = p_m(\mathbf{m})\, \left\|\frac{\partial \omega_h}{\partial \omega_o}\right\|
p o ( o ) = p m ( m ) ∂ ω o ∂ ω h
将反射项或透射项分别代入公式(4),最终可以得到各自的权重表达:
w e i g h t r ( o ) = f r ( i , o , n ) ∣ o ⋅ n ∣ p o ( o ) = F ( i , h r ) ∣ i ⋅ m ∣ G ( i , o , m ) ∣ i ⋅ n ∣ ∣ m ⋅ n ∣ \mathrm{weight_r}(\mathbf{o})=\frac{f_r(\mathbf{i},\mathbf{o},\mathbf{n})\left|\mathbf{o}\cdot\mathbf{n}\right|}{p_o(\mathbf{o})}=F(\mathbf{i},\mathbf{h}_\mathbf{r})\frac{\left|\mathbf{i}\cdot\mathbf{m}\right|G(\mathbf{i},\mathbf{o},\mathbf{m})}{\left|\mathbf{i}\cdot\mathbf{n}\right|\left|\mathbf{m}\cdot\mathbf{n}\right|}
weigh t r ( o ) = p o ( o ) f r ( i , o , n ) ∣ o ⋅ n ∣ = F ( i , h r ) ∣ i ⋅ n ∣ ∣ m ⋅ n ∣ ∣ i ⋅ m ∣ G ( i , o , m )
w e i g h t t ( o ) = f t ( i , o , n ) ∣ o ⋅ n ∣ p o ( o ) = ( 1 − F ( i , h t ) ) ∣ i ⋅ m ∣ G ( i , o , m ) ∣ i ⋅ n ∣ ∣ m ⋅ n ∣ \mathrm{weight_t}(\mathbf{o})=\frac{f_t(\mathbf{i},\mathbf{o},\mathbf{n})\left|\mathbf{o}\cdot\mathbf{n}\right|}{p_o(\mathbf{o})}=(1 - F(\mathbf{i},\mathbf{h}_\mathbf{t}))\frac{\left|\mathbf{i}\cdot\mathbf{m}\right|G(\mathbf{i},\mathbf{o},\mathbf{m})}{\left|\mathbf{i}\cdot\mathbf{n}\right|\left|\mathbf{m}\cdot\mathbf{n}\right|}
weigh t t ( o ) = p o ( o ) f t ( i , o , n ) ∣ o ⋅ n ∣ = ( 1 − F ( i , h t )) ∣ i ⋅ n ∣ ∣ m ⋅ n ∣ ∣ i ⋅ m ∣ G ( i , o , m )
虽然这种转换看着挺简单的,但是实际操作起来有着不少讲究。为了生成符合 p m p_m p m p m p_m p m c d f − 1 ( X ) cdf^{-1}(X) c d f − 1 ( X ) c d f − 1 ( X ) cdf^{-1}(X) c d f − 1 ( X )
这部分想要一下子搞清楚还挺不容易,所以一开始我并没有采用准确的 p m p_m p m
参考文献
Microfacet Models for Refraction through Rough Surfaces Physically Based Shading at Disney Background: Physics and Math of Shading PBR - LearnOpenGL CN PBRT: Transforming between Distributions