高性能计算:GPU上的BVH (2)
前文介绍了当前最高效的 GPU BVH 构建算法(LBVH)。这些方法通过对整个数组进行莫顿码预排序,从而避免了在 BVH 构建过程中对局部数据进行额外排序。此外,它们均采用了基数树的数据结构,并充分利用其特性,形成了极为高效的构建流程。
然而,尽管 LBVH 在构建速度上表现突出,却难以直接应用于高效的光线追踪场景。原因在于,LBVH 的设计仅以构建速度为唯一评价指标,而忽略了另一个关键因素——质量。一个高质量的 BVH 能够在层次遍历过程中更快速地实现剪枝,从而加快遍历速度,并减少候选碰撞图元的数量,这对于实时应用尤为重要。换言之,我们希望 BVH 的同级节点之间尽可能减少重叠区域,因为一旦光线进入重叠区域,就无法进行剪枝,必须依次遍历所有相关节点。
为了在 GPU 上构建高效且高质量的 BVH,我们需要引入 SAH(Surface Area Heuristic)。SAH 是一种用于 BVH 构建的启发式代价函数,其典型定位为:
其中,代表遍历一次BVH节点的代价,代表子空间中的图元数量,代表光线与图元一次求交的代价。
那么有没有办法在GPU 构建 BVH 的过程中,引入 SAH 以此提高最终 BVH 的质量呢?学术界对此有着广泛的研究,这便是本篇文章要介绍三种方法,分别是PLOC,PLOC++和HPLOC。论文链接放在文章末尾。
本文所讨论的 BVH 均为二叉树结构。而在当前的光线追踪器实现中,许多系统更倾向于采用多叉树结构的 BVH。关于多叉树的相关内容,本文不作展开讨论。
Parallel locally-ordered clustering (PLOC)
在前一篇文章的最后部分,我们介绍了 GPU 上自底向上构建 BVH 的方法。事实上,相较于自顶向下(划分式)的构建方式,GPU 算法更倾向于采用自底向上的策略。
谈到自底向上,就不得不引入 聚类(cluster) 的概念来辅助理解。对机器学习有所了解的同学对“聚类”一词一定不会陌生,它指的是由具有相似特征的元素组成的集合。在 BVH 的自底向上构建过程中,所有叶子节点首先各自形成一个仅包含自身的聚类。随后,每个聚类会寻找其最近邻聚类;若两个聚类互为最近邻,则合并为一个父节点。按照这一逻辑不断迭代,直到只剩下一个聚类,我们便完成了自底向上的 BVH 构建。
然而,若要为每个聚类寻找其全局最近邻节点,计算量将十分庞大。假设存在 个聚类,则该过程的时间复杂度为 。为降低最近邻搜索的开销,作者引入了一个搜索半径 :每个聚类仅在该半径范围内寻找最近邻。若两个聚类互为最近邻,则合并为父节点。通过这一策略,计算复杂度得以显著降低。
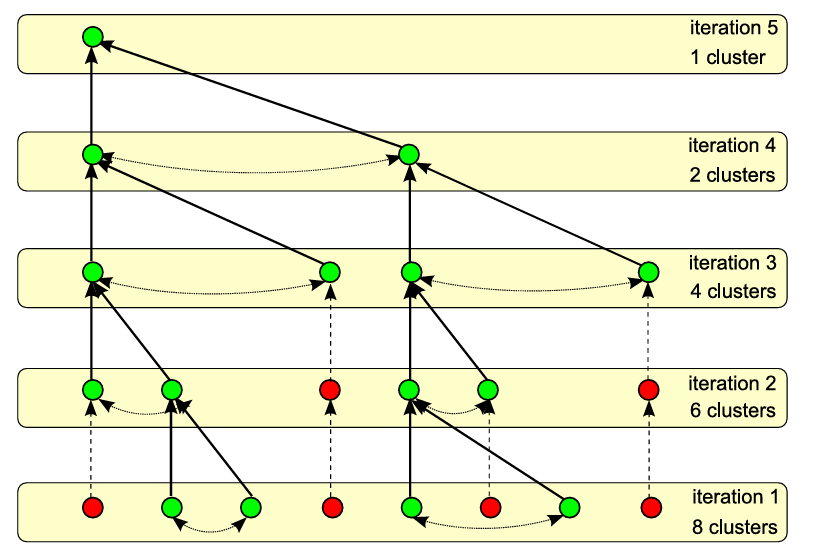
图例直观地展示了这一过程。在每次迭代中,绿色节点会找到与其互为最近邻的节点,并合并为父节点,作为下一轮迭代的输入;而红色节点若未能找到互为最近邻的对象,则直接复制到下一轮输入中。由此可见,迭代的过程本质上就是 BVH 的构建过程。
为避免confusion,后文中的“聚类”可直接理解为 BVH 的节点,两者不再做区分。
前期准备工作
现在我们对PLOC如何建BVH已经有了一个整体的认知,是时候补充其他必要的拼图了~
首先,我们需要一个性质良好的输入序列,以保证空间上的连续性。细心的读者可能已经意识到——没错,又到了神奇的莫顿码的登场时机了。
随后,我们需要为 BVH 节点(即一个聚类)定义一个距离函数,用于衡量其与同层级其他节点之间的关系。该函数的定义十分自然:直接取合并后节点的 AABB 包围盒的表面积即可。形式化表示为:
其中, 表示一个节点, 表示两个节点之间的距离, 表示节点的包围盒, 表示节点 1 与节点 2 合并后的节点, 表示包围盒的表面积。
显然,该距离函数满足以下性质:
当代价 分别为 与 在各自邻域中的最小值时,我们称它们互为最近邻。在这种情况下, 与 将在该轮迭代中合并为一个新的节点。
这里的聚类合并逻辑基于 AABB 包围盒的表面积,从而在构建 BVH 的过程中隐式地引入了 SAH 代价启发函数。
PLOC算法细节
从图示可以直观地看出,PLOC 算法是一个多轮迭代的过程。在每一轮迭代中,需要完成以下三个任务:
- 任务 1: 寻找最近邻,并将最近邻信息写入辅助数组;
- 任务 2: 合并互为最近邻的节点。合并结果写入索引较小的节点位置,而索引较大的节点位置则标记为无效(Invalid);
- 任务 3: 压缩任务 2 的输出,使结果紧密排列。
作者将这三个任务分别实现为三个独立的 CUDA Kernel(在 OpenGL 中对应为三个 Compute Shader),依次执行,每轮迭代的输出作为下一轮的输入。在整个程序运行过程中无需额外排序,因为任务 2 的合并操作并不会破坏莫顿码的空间布局。
实际上,这里所需的 CUDA Kernel 不止三个。尤其在处理大规模数据时,任务 3 至少需要三个 Kernel 才能完成。详细请查阅之前有关基数排序的文章。
在 GPU 上完成任务 1 和任务 2 相对容易,但任务 3 的实现却更具挑战性。为更好地解释任务 3 的逻辑,我们可以引入一个辅助缓冲区(尽管实际实现中并非必需)。具体而言,当任务 2 的输出缓冲区中某个元素有效时,将其在辅助缓冲区中标记为 1;若无效,则标记为 0。随后,对该辅助缓冲区执行一次 GPU 前缀和扫描,其结果即为压缩后节点在输出缓冲区中的位置索引。
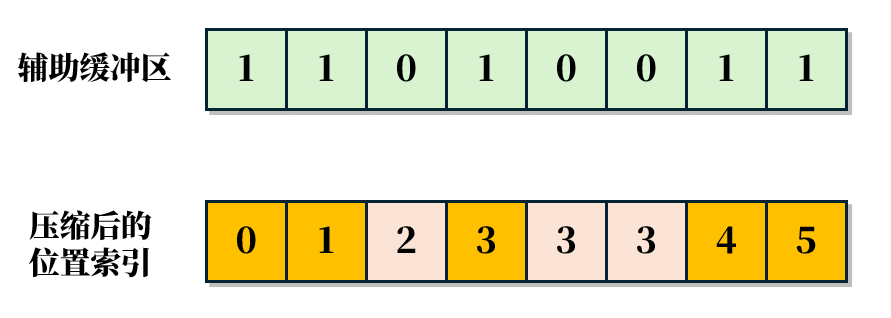
当迭代的输出仅剩一个节点时,迭代过程即告结束,PLOC 算法完成。
Parallel locally-ordered clustering++ (PLOC++)
从理论上看,PLOC 算法已经相当完备,但在具体的工程实现中仍存在优化空间。在 PLOC 的原始论文中,每轮迭代都需要依次调用三个独立的 CUDA Kernel(或 OpenGL Compute Shader)。随着迭代次数的增加,Kernel 之间的同步开销会不断累积,最终形成性能瓶颈。此外,PLOC 的邻域搜索策略也显得冗余。为此,PLOC++ 提出只需查询一个节点的半邻域,即可获得完整的最近邻信息,从而在计算量上实现近一倍的性能提升。
总体而言,PLOC++ 针对 PLOC 做了两方面的优化:
- 将原本的三个 CUDA Kernel 合并为一个;
- 将邻域搜索范围缩小了一半。
需要说明的是,优化 1 的表述在这里并不完全准确。实际情况是,PLOC 的任务 1 与任务 2 可以合并到同一个 Kernel 中,并且该 Kernel 还能同时计算输出数据的局部前缀和,从而显著减少任务 3 的计算量。
优化1:分块处理
那么,PLOC++ 究竟是如何实现将三个 CUDA Kernel 合并的呢?答案在于 分块(chunk)处理。
熟悉计算着色器的同学一定了解“工作组”的概念。PLOC++ 的优化实际上就是将数据分块处理(这里的数据就是BVH的节点,也就是前文一直提及的聚类),每个工作组负责处理各自的局部节点块。这样一来,所有中间数据都可以存储在共享内存中,从而显著提升数据访问效率。
为了保证能够在局部数据范围内计算出与 PLOC 中任务 1 和任务 2 完全一致的结果,每个工作组需要在其负责的节点块前后进行 Padding。具体而言,若最近邻搜索半径为 R,则除了本地节点块外,还需在前端额外填充前一个节点块的末尾 2R 个节点,在后端填充后一个节点块的起始 2R 个节点。
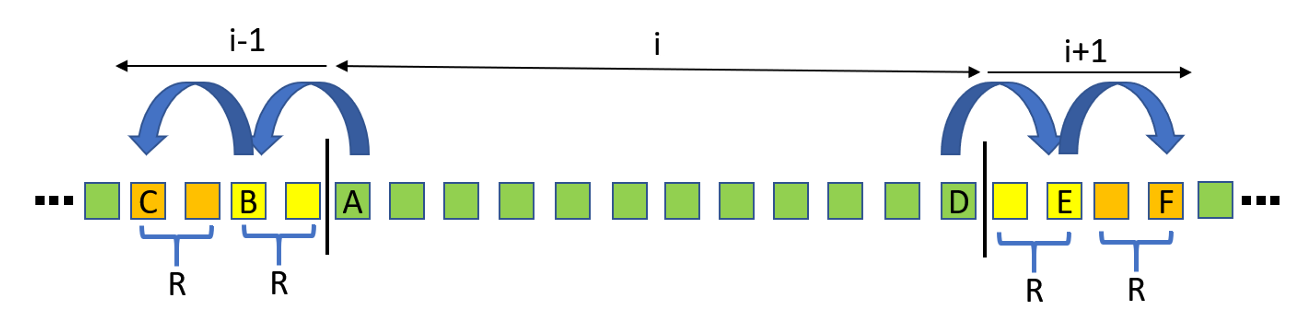
那么,为什么在首位需要 Padding 2R 个节点,而不是 R 个节点呢?这其中是有原因的。
回忆 PLOC 的任务 2:当找到一对互为节点最近邻的节点时,合并结果会写入索引较小的节点位置,即由前一个线程完成,而后一个线程则直接跳过。如果本地块首位仅 Padding R 个节点(图示中的黄色区域),则落在该区域的节点 B 可能会与本地节点块中的节点 A 形成最近邻对。在这种情况下,我们需要将 A 对应的辅助数组标记为 无效(Invalid),而 B 与 A 的合并逻辑则由前一个工作组完成。
然而,实际情况可能是节点 B 与节点 C 才是最近邻对,而它们的合并完全由前一个工作组负责。为了确保能够正确计算出最相邻的节点信息,我们必须在首位 Padding 2R 个节点。
聪明的同学可能会进一步追问:按照这样的逻辑,节点 C 是否也可能与更外层的节点形成最近邻对呢?确实如此。但在这里我们并不关心 C 的准确性,而只需保证本地节点块范围(例如 A 至 D)内的最近邻计算结果是正确的。
优化2:半领域搜索
在 PLOC 算法中,为了计算节点 的最近邻,我们需要依次评估代价 ,,其中 且 。然而,这样的计算方式存在大量冗余,因为 与 的数值必然相同。换言之,只需在计算 的同时,将结果同步告知节点,即可节省一半的计算量。
由此,搜索范围可以从 缩减为 。
PLOC++ 的论文还提到了一些额外的工程优化,例如在节点数量较少时仅分配一个工作组,以及双层 BVH 的构建等。对此感兴趣的读者可以进一步查阅原论文~
Hierarchical PLOC (HPLOC)
HPLOC(Hierarchical Parallel Locally-Ordered Clustering)是目前公认的 GPU 上构建 BVH 的 SOTA 算法之一,由 AMD 团队提出,并在 GPUOpen 平台上发布。
那么,H-PLOC 究竟是如何再次显著提升 BVH 的构建速度(达到 1.6–13 倍),并使其性能仅次于 LBVH 呢?答案在于 结合了 PLOC++ 与 LBVH 的构建过程。
早期的混合式 BVH 构建方法通常是根据输入规模选择不同的构建策略,例如小规模数据使用高质量构建,大规模数据使用高效构建。而 H-PLOC 的独特之处在于,它并非简单地在不同场景下切换算法,而是 在同一构建流程中充分融合了 LBVH 的高效性与 PLOC++ 的高质量性。
HPLOC给出一个非常清晰的示意图,这对我们理解HPLOC算法有很大的帮助。
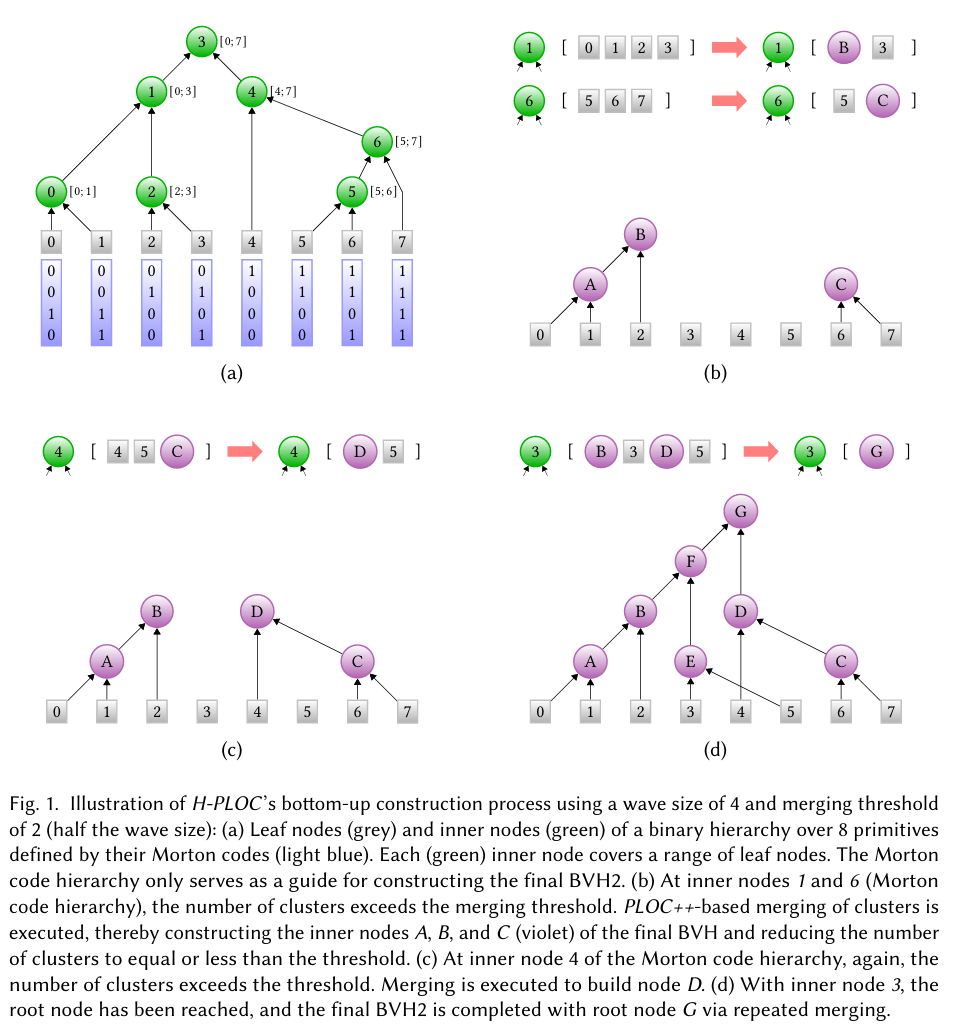
如图所示,H-PLOC 利用 LBVH 的基数树层次结构来指导 PLOC++ 的合并过程。在构建流程中,首先生成一个 LBVH,并设置一个 合并阈值。随后为所有叶子节点分配线程,并依次向上遍历。当某一区间的节点数量超过合并阈值时,便触发 PLOC++ 的合并操作,直到该区间内的节点数不大于阈值为止。
在图示 (b) 中,各线程向上遍历两层,抵达内部节点 1 和 6。此时,节点 1 对应区间 含有 4 个节点,节点 6 对应区间 含有 3 个节点,均超过合并阈值 2,因此执行 PLOC++ 的合并过程。合并得到的新节点 A、B、C 将作为最终 BVH 的一部分。通过迭代重复上述步骤,直至整个 BVH 构建完成。
在 LBVH 算法中,叶子节点与内部节点都会被纳入最终 BVH 结构;而在 H-PLOC 中,LBVH 的叶子节点才会作为最终 BVH 的节点,内部节点则仅作为抽象的辅助信息,不参与区间节点数量的统计。
如图 (a) 所示,内部节点 1 的两个子内部节点 0 和 2 并未用于数量统计。而由 PLOC++ 合并生成的新节点则会参与节点数量的统计,此时无需再对其子节点进行重复统计。
至此,我们对 H-PLOC 的 BVH 构建流程已有了较为清晰的认识,是时候深入算法的实现细节了。实际上,我们并不需要预先生成完整的 LBVH,而是在 LBVH 的生成过程中就融入 PLOC++ 的合并步骤。换言之,借助一些工程上的技巧,H-PLOC 能够在一次自底向上的构建过程中同时完成 LBVH 的生成与 PLOC++ 的合并,从而显著提升效率。
论文给出了详细的伪代码:


在算法 1 的第 9–26 行中,所实现的正是前文介绍的自底向上构建 BVH 的过程。不同之处在于,这里需要额外存储区间的字节节点划分位置。换言之,LBVH 的父节点不仅要计算自身的有效区间范围,还需额外记录一个划分位置(这里个人感觉有点Confusion,因为 LBVH 节点的索引本身就与区间划分密切相关)。
在完成一层 LBVH 的构建后,需要检查该层节点的区间大小是否超过合并阈值;若超过,则触发 PLOC++ 的合并过程。这部分实现细节在算法 2 中有更为完整的展示。
然而,尽管算法 2 给出了整体执行步骤,其中仍存在一些令人困惑的地方。例如:为什么要分别统计左区间与右区间的节点数量,而不是直接统计整个区间?统计函数是否经过优化?数据存储是否依旧与 PLOC++ 相同,即每层节点压缩后存放在缓冲区中?这些问题若要彻底解答,可能需要查阅源码或尝试自己实现一遍了。这也是只读论文的弊端了~
此外,H-PLOC 并不局限于二叉 BVH 的构建。论文中还提出了将 BVH 转换为宽 BVH(Wide BVH,即多叉结构)的方案。不过,这一部分已超出本文的讨论范围,因此不作展开。
参考文献
- Parallel Locally-Ordered Clustering for Bounding Volume Hierarchy Construction | IEEE Journals & Magazine | IEEE Xplore
- PLOC++: Parallel Locally-Ordered Clustering for Bounding Volume Hierarchy Construction Revisited: Proceedings of the ACM on Computer Graphics and Interactive Techniques: Vol 5, No 3
- H-PLOC Hierarchical Parallel Locally-Ordered Clustering for Bounding Volume Hierarchy Construction