前两篇文章分别介绍了 GPU 基数排序和莫顿码。随着这些前期准备工作的完成,我们终于可以进入正题——在 GPU 上构建 BVH。
在学术界,关于 GPU 构建 BVH 的研究成果十分丰富。论文1 Fast BVH Construction on GPUs 首次将莫顿码应用于 GPU 构建 BVH,并提出了 LBVH 与 SPH BVH 的构建方法。其中,LBVH 的构建过程需要在显存中执行多个步骤,例如多次排序以及后续的结构优化;而 SPH BVH 的 GPU 构建方法则在层次之间存在明确的依赖关系。以今天的视角来看,这些方法在某些方面已显得过时,但“利用莫顿码进行 GPU 构建 BVH”的核心思想却一直延续至今。
随后,论文2 Maximizing Parallelism in the Construction of BVHs, Octrees, and k-d Trees 提出了另一种高度并行的算法。作者借助有序基数树这一数据结构,成功消除了层次之间的数据依赖,使得 GPU 构建 BVH 的性能再次得到显著提升。时至今日,这种基于基数树的构建方式仍然是最快的BVH算法之一。
然而,即便论文 2 提出了高度并行的 GPU 基数树构建方法,我们仍然需要一个自底向上的过程来计算每个节点的 AABB 包围盒。论文 3 Fast and Simple Agglomerative LBVH Construction敏锐地捕捉到这一问题,作者设想:能否在基数树的构建过程中,将 AABB 包围盒的计算一并完成,只通过一次自底向上的遍历同时满足这两个需求?基于这一思路,作者在论文 2 的方法之上设计出了一套全新的算法,这应该是目前最快的 GPU LBVH 构建器。
CPU上的BVH构建
在 CPU 上构建 BVH 相对直观。我们可以直接定义一个结构体来描述 BVH 的节点:
1
2
3
4
5
6
7
8
9
10
| struct BVHNode {
BVHNode* left = nullptr;
BVHNode* right = nullptr;
bool isLeaf = false;
AABB aabb;
Range range;
};
|
在划分 BVH 节点时,通常会采用启发式的方法来确定左右子节点的分割点。例如,可以依据 AABB 的最长轴进行划分,或者利用 SAH(Surface Area Heuristic) 代价函数来选择最优的分割方式。整体构建过程可以表示为如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| BVHNode* BuildBVH(int first, int last) {
if (first == last) {
return CreateLeafNode(first);
}
BVHNode* node = new BVHNode();
node->range = Range(first, last);
node->aabb = ComputeAABB(node->range);
int split = FindSplit(node->range);
node->left = BuildBVH(first, split);
node->right = BuildBVH(split + 1, last);
return node;
}
|
在寻找子节点的划分位置时,往往需要按照某种规则对数据进行排序或分组。通过这种方式,我们就能够在 CPU 上逐步构建出完整的 BVH。
那么,CPU 上的这种构建方式是否能够直接应用于 GPU 的 BVH 构建呢?答案显然是否定的。首先不论 FindSplit 是否涉及大量的小范围排序,GPU 的架构本身就不适合这种指针式的递归构建方式。由于 GPU 并不支持指针,我们必须将 BVH 构建在一个线性数组中。这种基于线性存储的 BVH 构建方式被称为 LBVH(Linear BVH),这也是本篇文章的主角~
覆盖率(Occupancy)
在进入本篇文章的正题之前,我想先解释一下为什么 论文 2 要消除 论文 1 算法中层级之间的依赖关系。假设 BVH 的层次结构是一个完全二叉树,如果在 GPU 上逐层构建,那么实际上就是在执行一次广度优先搜索。通常情况下,这样的构建过程可以描述为:
- 并行构建当前层级的所有节点;
- 当节点构建完成后,通过原子加法统计并添加下一层级的节点数量信息;
- 并行构建下一层级的所有节点。
这种构建过程是一种非常自然且直观的思路。在叶子节点层级,由于节点数量庞大,GPU 能够充分发挥其高度并行的计算优势,从而高效完成 BVH 的构建。
然而在层次结构的顶层节点,GPU 的利用率却不够理想。通常我们会为每个节点分配一个 GPU 线程,但在根节点层级(第 0 层)仅有一个节点,只需一个线程即可,此时大量线程处于闲置状态。同样地,在第二层也仅有两个线程处于活跃状态。
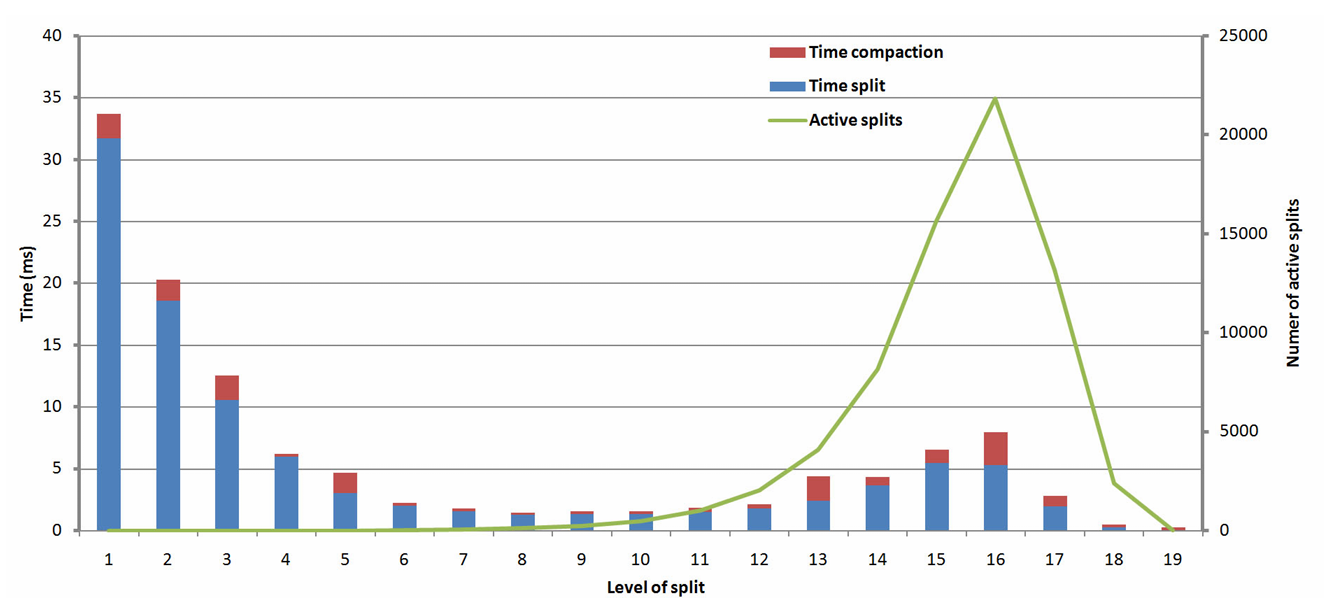
论文 1 给出了各个层级的构建耗时,可以发现顶层的构建时间远远大于其他层次。这是因为顶层的线程需要在一个大范围的数据中寻找子节点的划分点,而随着层次的增加,活跃线程数量逐渐增多,GPU 开始进入高度并行状态,各线程所处理的数据范围也随之缩小。
我们将活跃线程占总线程的比例称为 GPU 的 覆盖率(Occupancy)。一个优秀的 GPU 算法,应当尽可能保持较高的覆盖率,以充分发挥硬件的并行计算能力。
基数树(Radix Tree)
论文 2 引入了 基数树(Radix Tree) 这一数据结构,有效解决了论文 1 中顶层节点 GPU 覆盖率过低的问题。那么,基数树究竟是什么样的结构?它又具备哪些独特的性质呢?
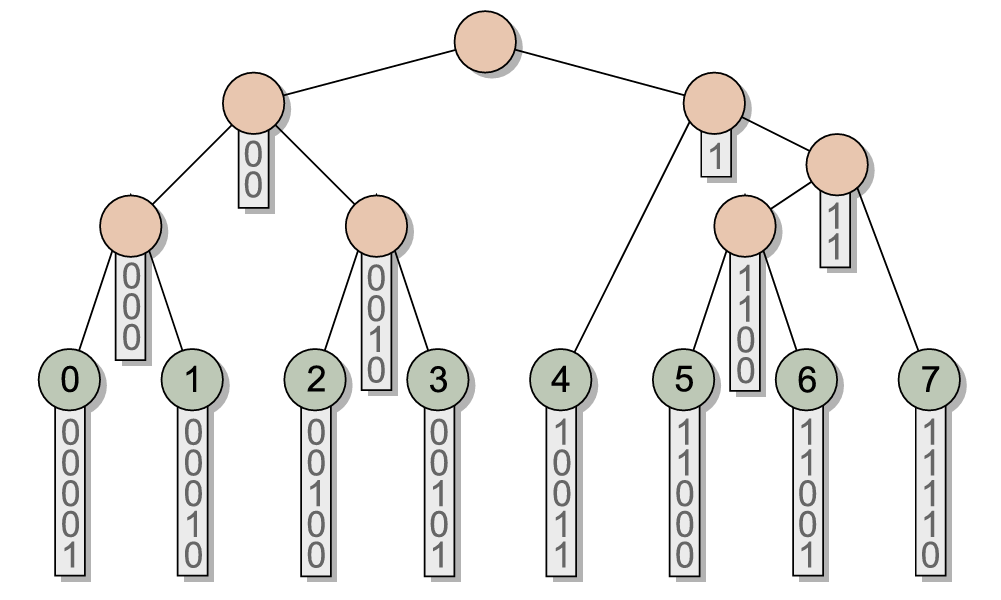
图中为论文2中一个基数树的示例。注意,图中的叶子节点就是我们的输入数据,因此我们需要保证用于构建基数树的输入序列是有序的。
假设输入序列的元素个数为 n,基数树具有以下性质:
- 叶子节点序列与输入序列一致,且保持有序;
- 内部节点(除叶子节点外的所有节点)的数量为 n−1;
- 每个内部节点记录其对应序列范围的最大公共前缀长度。
有了这些性质之后,我们会惊讶地发现:如果根据最大公共前缀长度来划分序列范围,就能够自然地形成一种层次结构。而这种层次结构几乎可以无缝地映射为 BVH !
现在我们需要理解基数树是如何根据最大公共前缀长度来划分序列范围。定义操作 δ(i,j) 表示序列区间 [i,j] 的最大公共前缀长度。例如,在图示中 δ(3,4)=0,因为这两个元素没有任何公共前缀。
那么,划分位置应当如何确定呢?得益于输入序列是有序的,我们可以得到如下性质:若i≥i′,且 j≤j′,则有 δ(i,j)≤δ(i′,j′),。因此,在区间 [i,j] 内必然存在一个位置 γ,满足 i≤γ<j,并且 δ(y,y+1)=δ(i,j)。这个 γ 就是区间 [i,j] 的划分点。
例如δ(0,7)=δ(3,4)=0,所以3即位序列范围[0,7]的划分点。
CPU上的基数树
在 CPU 上构建基数树相对容易。我们可以定义一个类似 BVH 节点的结构体,用于表示基数树的节点,并递归地完成整体构建:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| struct RadixTreeNode {
RadixTreeNode* left = nullptr;
RadixTreeNode* right = nullptr;
bool isLeaf = false;
Range range;
Prefix prefix;
};
RadixTreeNode* BuildRadixTree(int first, int last) {
if (first == last) {
return CreateLeafNode(first);
}
RadixTreeNode* node = new RadixTreeNode();
node->range = Range(first, last);
node->prefix = ComputePrefix(node->range);
int split = FindSplit(node->range);
node->left = BuildRadixTree(first, split);
node->right = BuildRadixTree(split + 1, last);
return node;
}
|
GPU上的基数树
与 CPU 上的 BVH 构建类似,基于指针的递归算法并不适合直接迁移到 GPU。一方面,GPU 架构本身不支持指针操作;另一方面,这种递归逻辑本质上存在明确的层级依赖关系,限制了并行度。
论文 2 提出了一种高效的并行算法:只需输入有序序列,无需额外的辅助数据结构,即可在原地一次性构造出所有内部节点和叶子节点。这种方法不仅消除了层级依赖问题,还充分发挥了 GPU 的并行计算能力。
假设输入的有序序列长度为 n。为了存储所有内部节点和叶子节点的信息,我们需要在显存中创建两个数组:
在数组 I 中,位置 I0 始终表示根节点。设根节点 I0 的划分位置为 l,则 Il 和 Il+1 分别对应根节点的左右子节点。依此类推,整个树的层次结构都可以通过这种方式在数组中顺序表示。
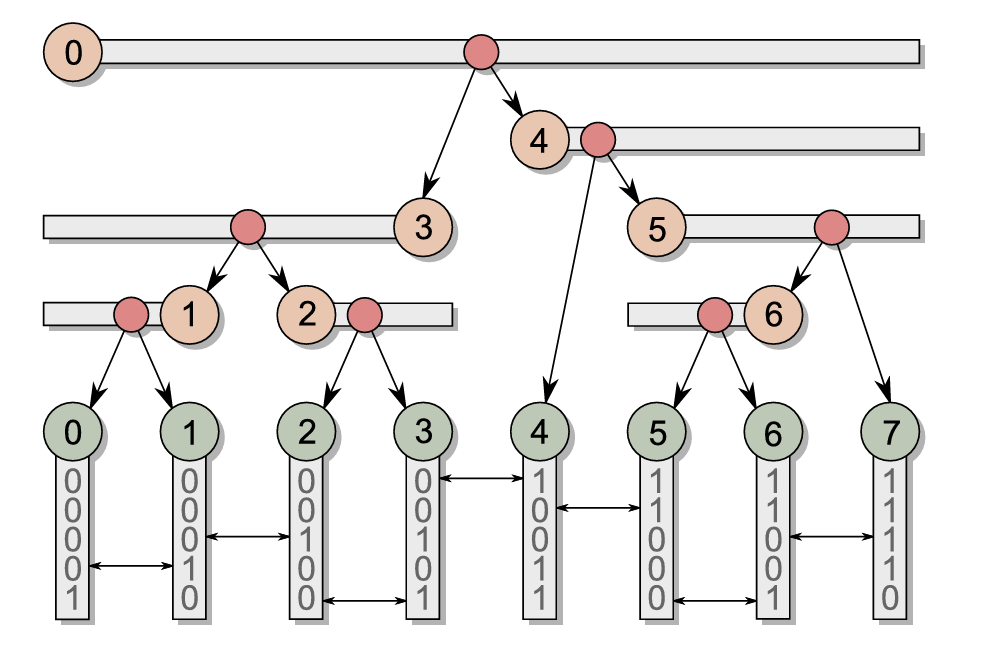
示意图展示了所有节点在数组 I 和 L 中的存储位置。我们更关注数组 I 的存储格式特点。
通过观察可以总结出以下性质:
- 性质 1: 左子树的存储位置对应其内部节点序列范围的右边界;
- 性质 2: 右子树的存储位置对应其内部节点序列范围的左边界;
- 性质 3: 当 δ(k−1,k)>δ(k,k+1) 时,节点 Ik 为左子树节点;
- 性质 4: 当 δ(k−1,k)<δ(k,k+1) 时,节点 Ik 为右子树节点;
- 性质 5: 子节点序列范围的最大公共前缀长度始终大于父节点。
利用这五条性质,我们可以总结出 GPU 构建基数树的整体逻辑:
对于数组 I 中的每一个内部节点,并行执行以下步骤:
- 判断当前节点属于左子树还是右子树;
- 计算该节点序列范围上界;
- 确定序列范围的另一端点;
- 找到子树的划分位置;
- 在 I 和 L 中输出子节点(内部节点或叶子节点)的信息。
在第一步判断子树类型的过程中,作者引入了一个 方向 d 的概念。该方向决定了在确定序列的另一端点时,是向前还是向后搜索:
- 当内部节点属于左子树时,设定 d=−1,需要向前查找序列的端点;
- 当内部节点属于右子树时,设定 d=1,需要向后查找序列的端点。
作者在论文中也给出了完整算法的伪代码:

在第二步中,我们利用 性质 5 来确定序列范围的上界。接着在第三步中,基于该上界采用 倍增法 来寻找序列的另一端点。得到完整的序列范围后,再在第四步中借助类似 二分查找 的思想,确定新的划分位置。
GPU上的LBVH
在理解了 GPU 上基数树的构建算法之后,我们可以进一步探讨如何在此基础上构建 BVH。整体流程非常简洁,只需四个步骤:
- 计算输入图元的 Morton 码;
- 根据 Morton 码进行排序;
- 将排序后的图元序列作为输入,执行基数树构建算法;
- 自底向上地构建 AABB。
自底向上构建AABB(Bottom-up)
在完成基数树的构建之后,我们仍需为每个节点(包括内部节点与叶子节点)生成对应的 AABB 包围盒。由于论文中仅给出了计算逻辑,而未提供实现细节(例如是否需要辅助数组等),因此我们可以合理假设:所有节点均保存其父节点的索引,以便在自底向上的过程中完成包围盒的合并与更新。
由于基数树本质上是二叉树,因此每个内部节点必然拥有两个子节点。AABB 的计算从叶子节点开始,完成后将结果传递至父节点(在 GPU 中通过显存记录)。由于父节点需要接收两个子节点的输入,并最终输出一个 AABB,我们必须协调线程的执行:第一个完成传递的子节点线程应立即退出,而由第二个线程继续完成父节点的 AABB 合并与输出。
具体而言,每个父节点维护一个原子计数器,初始值为 -1。第一个进入的线程将计数器加 1 使其变为 0,随后退出;而第二个线程在检测到计数器为 0 时,便确认自己是后续执行者,从而继续完成父节点的计算。
实验结果
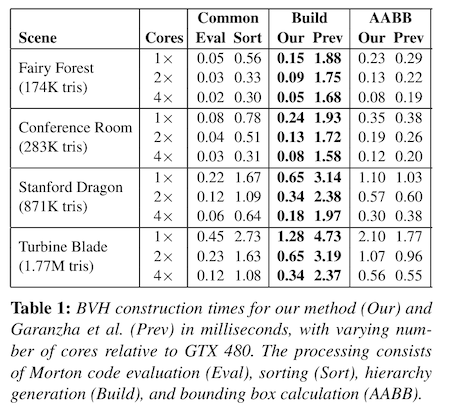
作者给出了各步骤在不同场景下的 GPU 性能开销(单位:毫秒)。结果显示,在 LBVH 的构建阶段,性能提升约一个数量级。
自底向上构建基数树
前述算法在性能上已相当出色,但既然我们始终需要自底向上地构建 AABB,那么为何不在一开始就采用自底向上的方式,同时完成基数树与 AABB 的构建呢?基于这一思路,论文 3 提出了全新的 LBVH 构建算法。
作者在此仍然使用了两个与论文 2 大小相同的缓冲区 L 和 I,其中 L 用于存储叶子节点,I 用于存储内部节点。不过,与论文 2 不同的是,这里的 I 不再表示内部节点划分范围的某个端点,而是直接表示划分位置。例如,I0 表示内部节点 0 在叶子节点 0 与叶子节点 1 之间的划分。
每个内部节点都会维护一个序列范围,用以表示其子树所覆盖的连续图元索引区间。如此依赖,我们便不必用论文 2 中的算法显示计算区间的另一个端点了。
另一处差异体现在 δ 函数的定义上。在论文 2 中,δ(i,j) 表示区间 [i,j] 的最大公共前缀长度;而在本文中,δ(i) 则用于表示内部节点 i 所对应区间的最后一位 k 与 k+1 的最高不同位。例如,δ(2)=δ(2,3)。为了统一表述,我们在此仍沿用论文 2 中的定义。
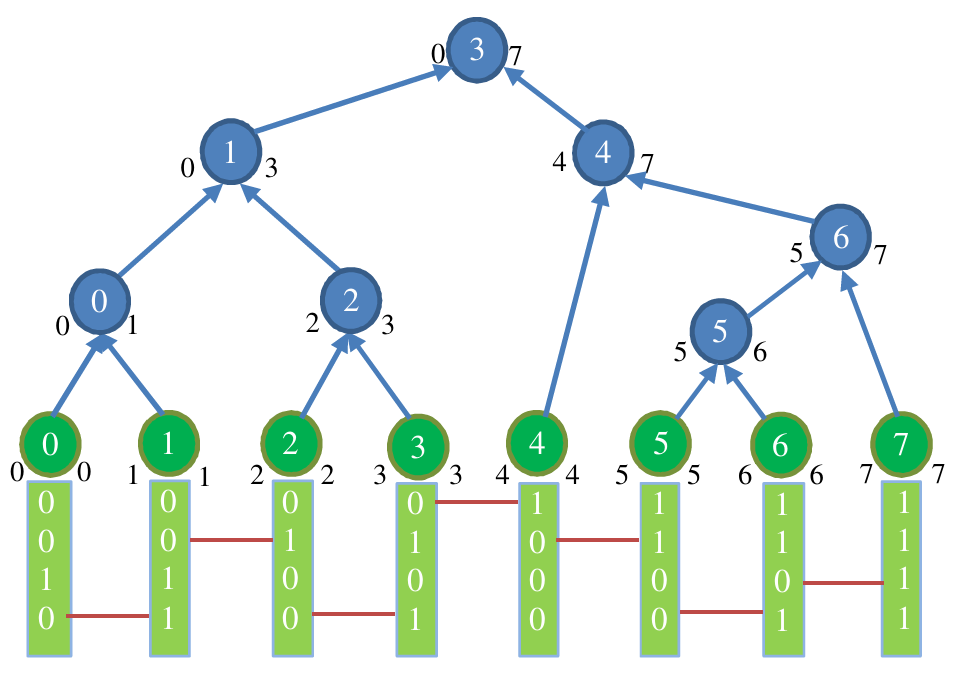
重新界定数据含义后,结合图例,设某节点的区间范围为 [i,j],可以总结出以下性质:
- 性质 1: 当 δ(i−1,i)<δ(j,j+1) 时,该节点为左孩子,其父节点为 Ij;
- 性质 2: 当 δ(i−1,i)>δ(j,j+1) 时,该节点为右孩子,其父节点为 Ii−1;
- 性质 3: 叶子节点 L0 的父节点始终为 I0。
有了这三条性质,我们也就自然而然地构建出了自底向上的LBVH构建逻辑。
与论文 2 中自底向上计算 AABB 的逻辑类似,我们同样需要为每个节点设置一个原子计数器。仅允许第二个抵达的子节点线程继续执行后续步骤;而每个子节点则需向父节点提供区间的一个端点以及对应的 AABB 信息。通过这一机制,我们得以完整实现 GPU 上自底向上构建 LBVH 的流程。
注意到我们只需要 δ(k,k+1) 的结果,因此这一部分可以提前预计算。
用GPU构建LBVH
参照论文3,我在 GLSL 中实现了一版简易的 GPU LBVH 构建器。整体流程如下:
- 为每个三角形生成莫顿码;
- 对莫顿码进行排序;
- 计算 δ;
- 根据莫顿码与 δ 自底向上构建 LBVH。
前两个步骤并非本文的重点,感兴趣的读者可参考我前两篇文章。 而后两个步骤则分别需要一个计算着色器来完成。
步骤三:计算 δ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #version 460
layout (local_size_x = 512, local_size_y = 1, local_size_z = 1) in;
layout(std430, binding = 1) buffer Morton3DBuffer { uvec2 Morton3D[]; };
layout(std430, binding = 3) buffer AuxiliaryBuffer { int Root; int Delta[]; };
uniform int uElementCount;
int ComputeDelta(uint i)
{
uvec2 first = Morton3D[i - 1];
uvec2 second = Morton3D[i];
uint high = first.x ^ second.x;
uint low = first.y ^ second.y;
if (high != 0u)
{
return 31 - findMSB(high);
}
else if (low != 0u)
{
return 32 + (31 - findMSB(low));
}
return 64;
}
void main()
{
uint globalID = gl_GlobalInvocationID.x;
int N = uElementCount;
if (globalID > N) return;
if (globalID == 0) {
Delta[0] = -1;
}
else if (globalID == uint(N)) {
Delta[N] = -1;
}
else {
Delta[globalID] = ComputeDelta(globalID);
}
}
|
步骤四:自底向上构建 LBVH
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| #version 460
layout (local_size_x = 512, local_size_y = 1, local_size_z = 1) in;
struct Triangle{
vec4 P1, P2, P3;
vec4 N1, N2, N3;
ivec4 MaterialSlot;
};
struct LBVHNode{
ivec4 Param1;
ivec4 Param2;
vec4 AABB_MinPos;
vec4 AABB_MaxPos;
};
layout(std430, binding = 0) buffer TriangleBuffer { Triangle Triangles[]; };
layout(std430, binding = 1) buffer Morton3DBuffer { uvec2 SortedMorton3D[]; };
layout(std430, binding = 2) buffer LBVHNodeBuffer { LBVHNode BVHNodes[]; };
layout(std430, binding = 3) buffer AuxiliaryBuffer { int Root; int Delta[]; };
layout(std430, binding = 4) buffer AtomicFlagBuffer { int AtomicFlags[]; };
uniform int uElementCount;
bool IsLeftChild(ivec2 Range)
{
return Delta[Range.x] < Delta[Range.y + 1];
}
bool IsRootNode(ivec2 Range)
{
return Range.x == 0 && Range.y == uElementCount - 1;
}
bool IsLeafNode(int NodeID)
{
return NodeID < uElementCount;
}
void InitLBVHNodes(int NodeID)
{
uvec2 Morton3D = SortedMorton3D[NodeID];
Triangle t = Triangles[Morton3D.y];
LBVHNode Node;
Node.Param1 = ivec4(-1, -1, 1, 0);
Node.Param2 = ivec4(NodeID, NodeID, 0, 0);
Node.AABB_MinPos = min(t.P1, min(t.P2, t.P3));
Node.AABB_MaxPos = max(t.P1, max(t.P2, t.P3));
BVHNodes[NodeID] = Node;
}
void main()
{
uint globalID = gl_GlobalInvocationID.x;
int N = uElementCount;
if(globalID >= N) return;
InitLBVHNodes(int(globalID));
if (N == 1) {
if(globalID == 0) Root = 0;
return;
}
int CurrNodeID = int(globalID);
for(int i = 0; i < 64; i++)
{
LBVHNode CurrNode = BVHNodes[CurrNodeID];
ivec2 CurrRange = CurrNode.Param2.xy;
int ParentLocalID;
bool isLeft = IsLeftChild(CurrRange);
if (isLeft) ParentLocalID = CurrRange.y;
else ParentLocalID = CurrRange.x - 1;
int ParentGlobalID = ParentLocalID + N;
int BroNodeID = atomicAdd(AtomicFlags[ParentLocalID], CurrNodeID + 1);
if (BroNodeID == -1) return;
LBVHNode BroNode = BVHNodes[BroNodeID ];
ivec2 BroRange = BroNode.Param2.xy;
LBVHNode Node;
if (isLeft){
Node.Param1 = ivec4(CurrNodeID, BroNodeID, 0, 0);
Node.Param2 = ivec4(CurrRange.x, BroRange.y, 0, 0);
}
else{
Node.Param1 = ivec4(BroNodeID, CurrNodeID, 0, 0);
Node.Param2 = ivec4(BroRange.x, CurrRange.y, 0, 0);
}
Node.AABB_MinPos = min(CurrNode.AABB_MinPos, BroNode.AABB_MinPos);
Node.AABB_MaxPos = max(CurrNode.AABB_MaxPos, BroNode.AABB_MaxPos);
BVHNodes[ParentGlobalID] = Node;
if (IsRootNode(Node.Param2.xy)) {
Root = ParentGlobalID;
return;
}
CurrNodeID = ParentGlobalID;
}
}
|
可视化LBVH
可视化一下用 GPU 构建的 LBVH ~
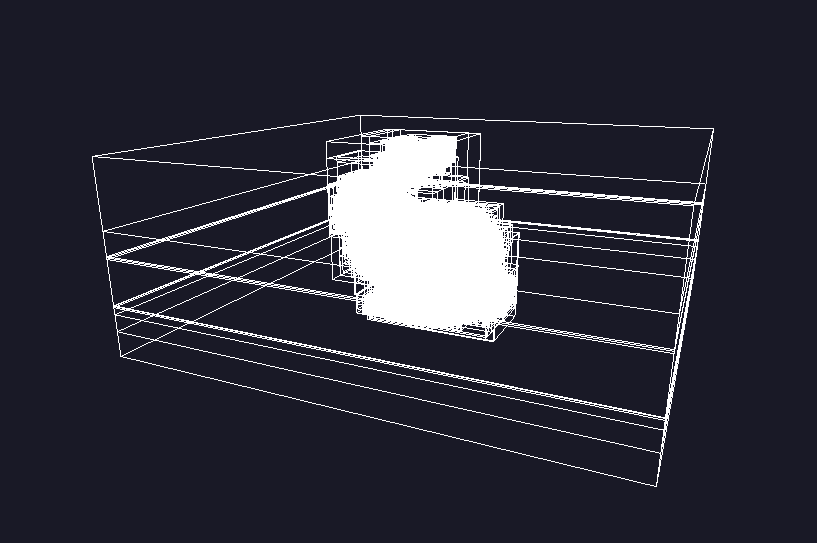
看着没啥问题,和用 CPU 构建的 LBVH 一样。
再跑个简单的相交测试:
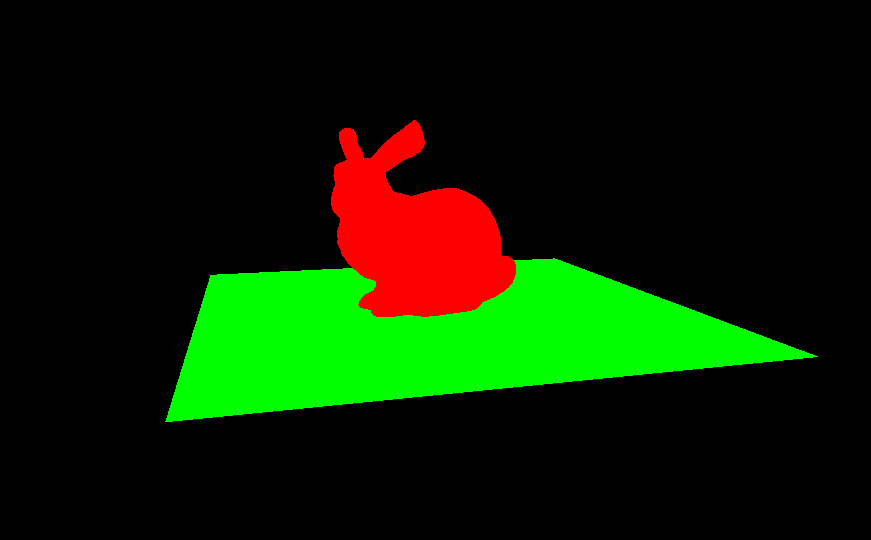
符合预期的结果,也是终于把 GPU BVH 这块看的差不多了,可以愉快地写光追了orz。
完整代码已上传 GPU LBVH Builder
参考文献
- Fast BVH Construction on GPUs
- Maximizing Parallelism in the Construction of BVHs, Octrees, and k-d Trees
- Fast and Simple Agglomerative LBVH Construction